1.2 宏观层面的AI技术发展趋势
1.2.0 预训练时代的终结和后续展望
- 根据Ilya Sutskever于2024年12月在NeuralIPS 2024上的分享总结
- 预训练时代(Age of Pre-Training)
- 核心是训练越来越大的模型
- GPT-2, 2019;GPT-3, 2020;Scaling Law, 2020
- 预训练时代必将迎来终结
- 算力在增长:更好的硬件GPU、更好的算法、更大的数据中心
- 数据并没有增加:只有一个互联网,数据像是AI的石油,正在被耗尽
- 预训练时代之后
- Agent
- 合成数据(Synthetic Data)
- Inference Time Compute(o1等推理模型)
- 除了目前已经发现的三种Scaling因素,未来可能会发现新的Scaling因素
- 超级智能(Superintelligence)
- Agentic
- Reasoning
- 模型推理的越多,它的结果就越不可预测
- 过往所有深度学习的结果都是可预测的,因为它在尝试复制人类的直觉
- 我们未来会需要和高度不可预测的AI打交道
- Understand
- Self Awareness
1.2.1 开源与闭源之争
- 什么是开源?
- 在软件社区中,”开源”是指根据许可证发布的软件,该许可证授予用户自由使用、研究、修改和分发软件及其源代码的权利。开放权重模型虽然比封闭权重模型对开发者更友好,但不一定是完全开源的,因为底层代码或训练数据通常不公开。
- 开源的方法根据其开放程度从低到高排列,可以分为公开训练好之后的模型权重(Weights)、公开训练数据集、公开训练代码
-
DeepSeek vs Qwen vs Llama同是开源,有什么区别?
特征 Llama 3 Qwen2 DeepSeek 许可名称 Llama 3 Community License Apache 2.0 License MIT License & DeepSeek Model License Agreement 商用 允许,由用户数量限制 允许 允许 限制 如果产品或服务每月活跃用户(MAU)超过 7 亿,必须向 Meta 申请特殊许可。训练限制:不能使用 Llama 3 的输出来训练或改进另一个大型语言模型。 无。Apache 2.0 许可证是一个标准的、高度宽松的开源许可证,它不会根据用户群规模做出任何限制。 MIT 许可证:几乎没有。它是最宽松的开源许可证之一。DeepSeek 自定义许可证:包含一系列基于使用的限制(禁止有害/非法应用程序) 模型修改 允许 允许 允许
- 在2022-2023年,闭源模型GPT3.5/GPT-4性能比开源模型领先很多,而此后闭源模型的领先优势在持续收窄,2025年1月DeepSeek-R1的出现向世人印证了这一点。更多关于闭源与开源模型的性能差异变化的内容请见章节1.1.1。
- 开源模型的优势在于其被学界、社会各界的广泛微调、使用、持续改进。开源模型有可能能够帮助AI应用公司降低模型使用成本,模型可以被免费部署于AI应用公司自己的服务器上,仅需承担服务器的运营维护费用。但开源及闭源模型的成本在不断下降,自行部署模型的价格优势还能保持多久仍是未知的,最终两者的价格可能会收敛到一个”市场均衡”价格。如果是为了简化团队规模,直接使用模型公司提供的API可能是更加经济的选择。更多关于AI推理成本下降造成的影响的内容请见章节2.2.1。
1.2.2 数据是模型发展的”石油”——如果”石油”被用完了怎么办?
- 此部分内容的参考主要来自AI Index Report 2025
-
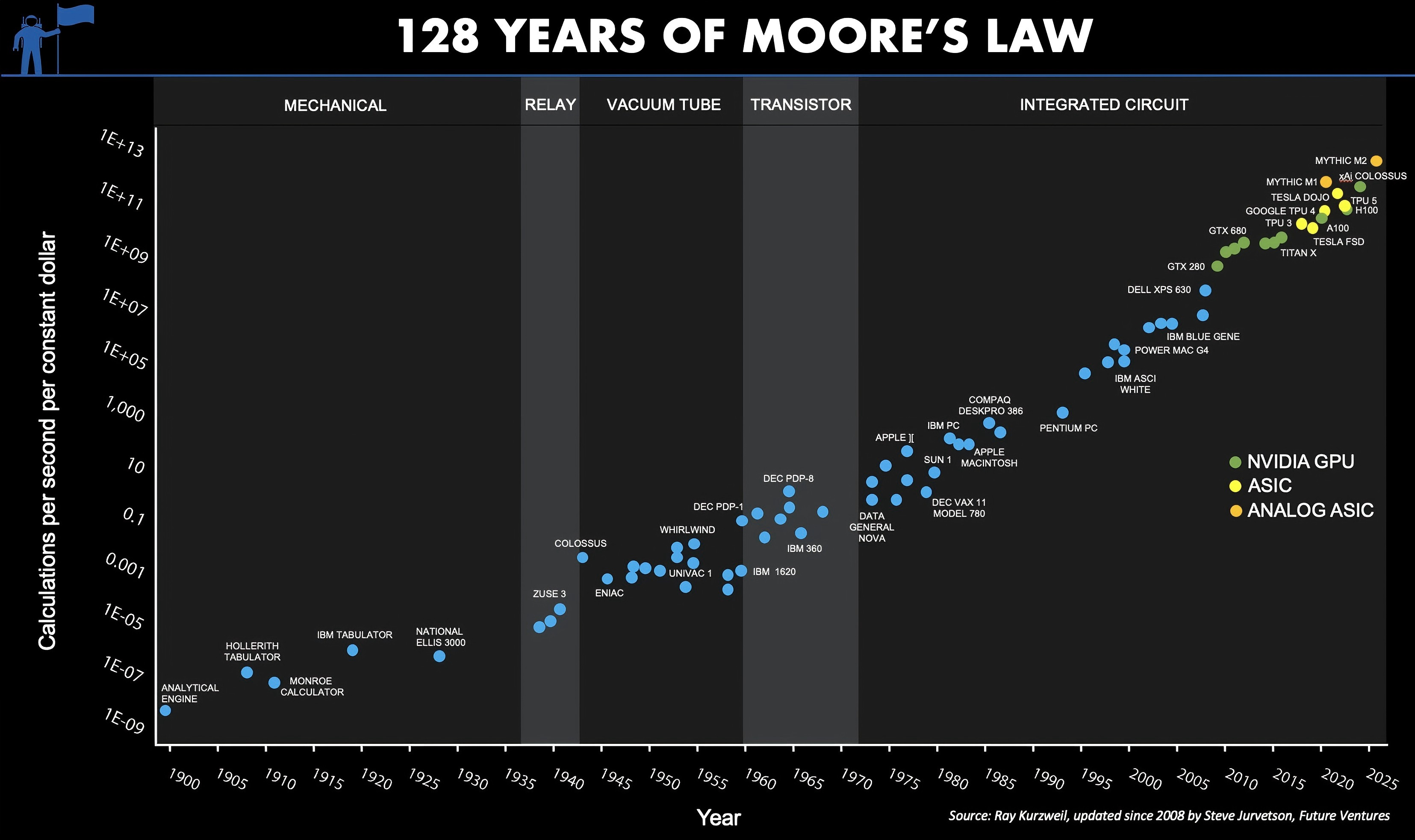
曾经主流观点是限制Scaling Up的主要因素是算力,即GPU的性能和供给。但实际上如今GPU性能仍大致遵循着Moore’s Law保持着稳定且持续增长的态势,2024年初公布的Nvidia Blackwhell将在上一代产品Nvidia Hopper的基础上再将模型训练性能提升4倍,Nvidia GPU产能也在逐步提升。但由于训练数据的规模巨大,其产生速度已经逐渐难以跟上消耗的速度了,并逐渐可能成为新的Scale Up瓶颈。
-
人类只有一个互联网,人类创造的”数据”就如同”石油”一般可能会被消耗殆尽,现存数据及人类产生新数据内容的速度可能无法满足模型训练数据继续快速scale up的需求。此外,随着内容版权的争夺,许多网站开始限制其内容被使用于AI模型训练,使用技术手段阻止数据爬虫、通过法律手段起诉违规使用其数据的组织,或寻求数据的付费使用,从而形成一堵”数据墙”。
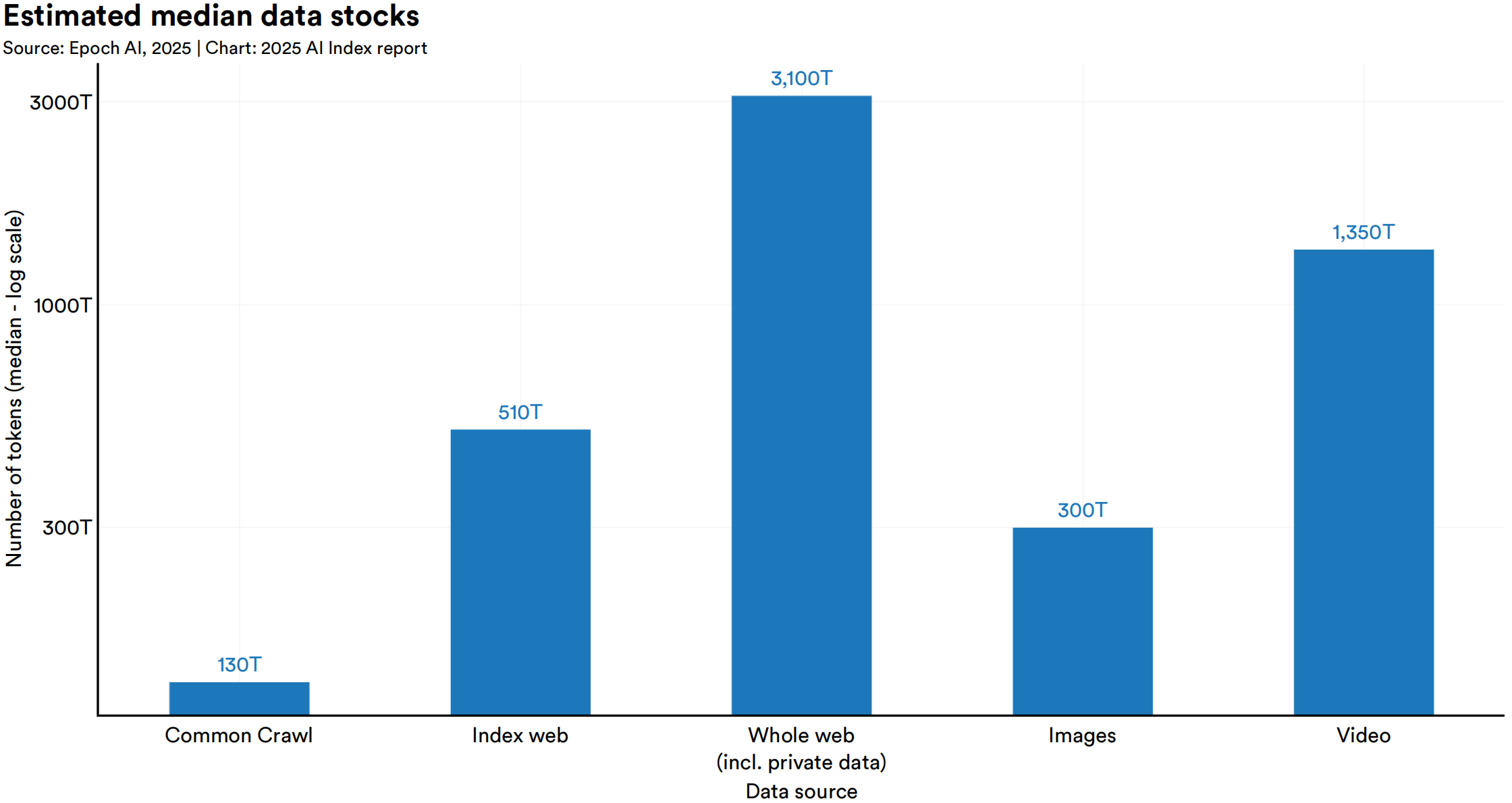
- 根据Epoch AI预测,预计现有的训练数据将在 2026 年至 2032 年间被完全使用,请见相关论文。
-
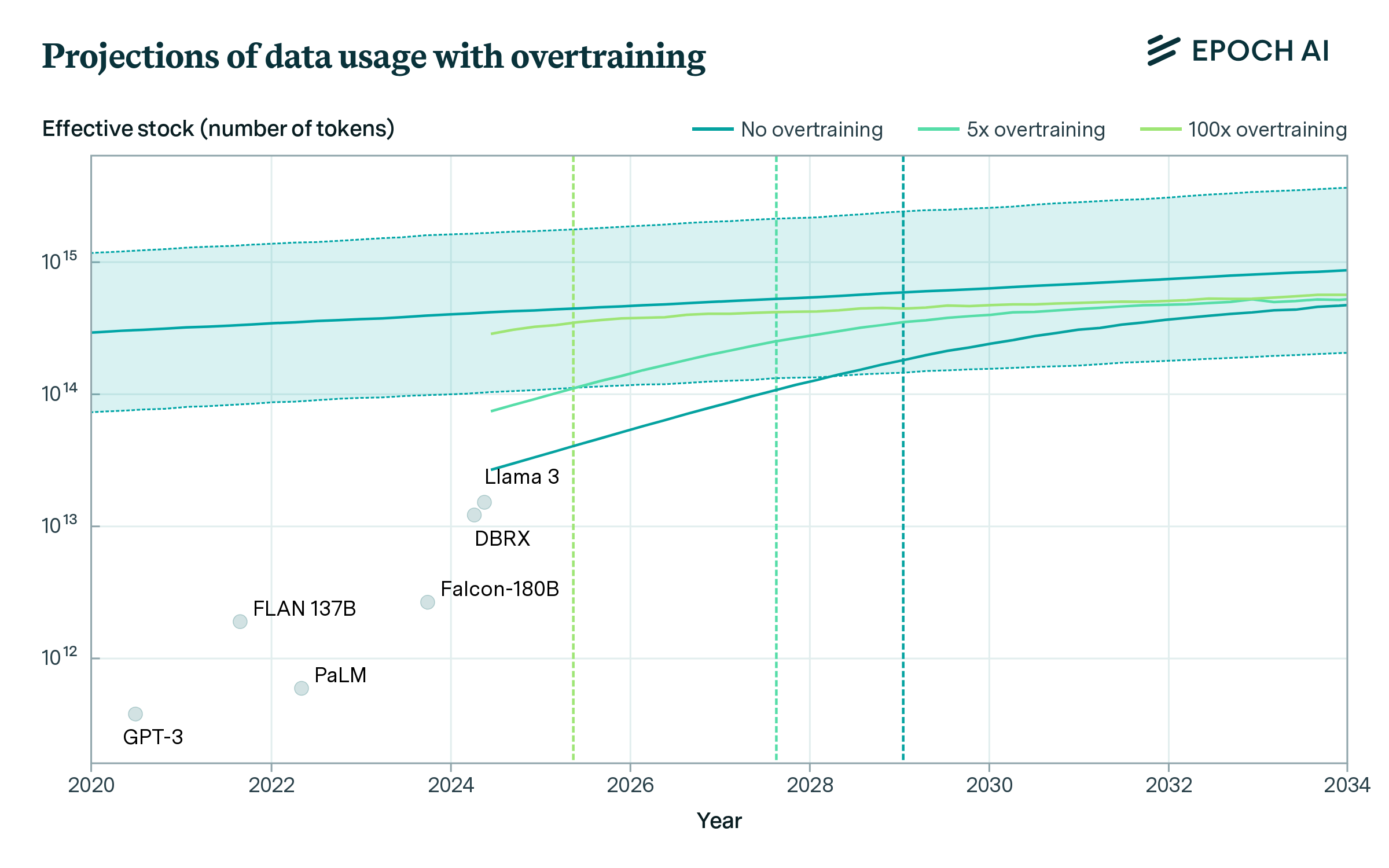
以计算最优方式训练的模型,模型的每个参数需要对应大约 20 个token进行训练。在这种假设下,互联网上有足够的数据来训练10 Trillion PetaFLOP(即$10^{28}$ FLOP)计算量的模型,预计在 2028 年模型计算量将达到这一水平,即数据将于2028年被用尽。
-
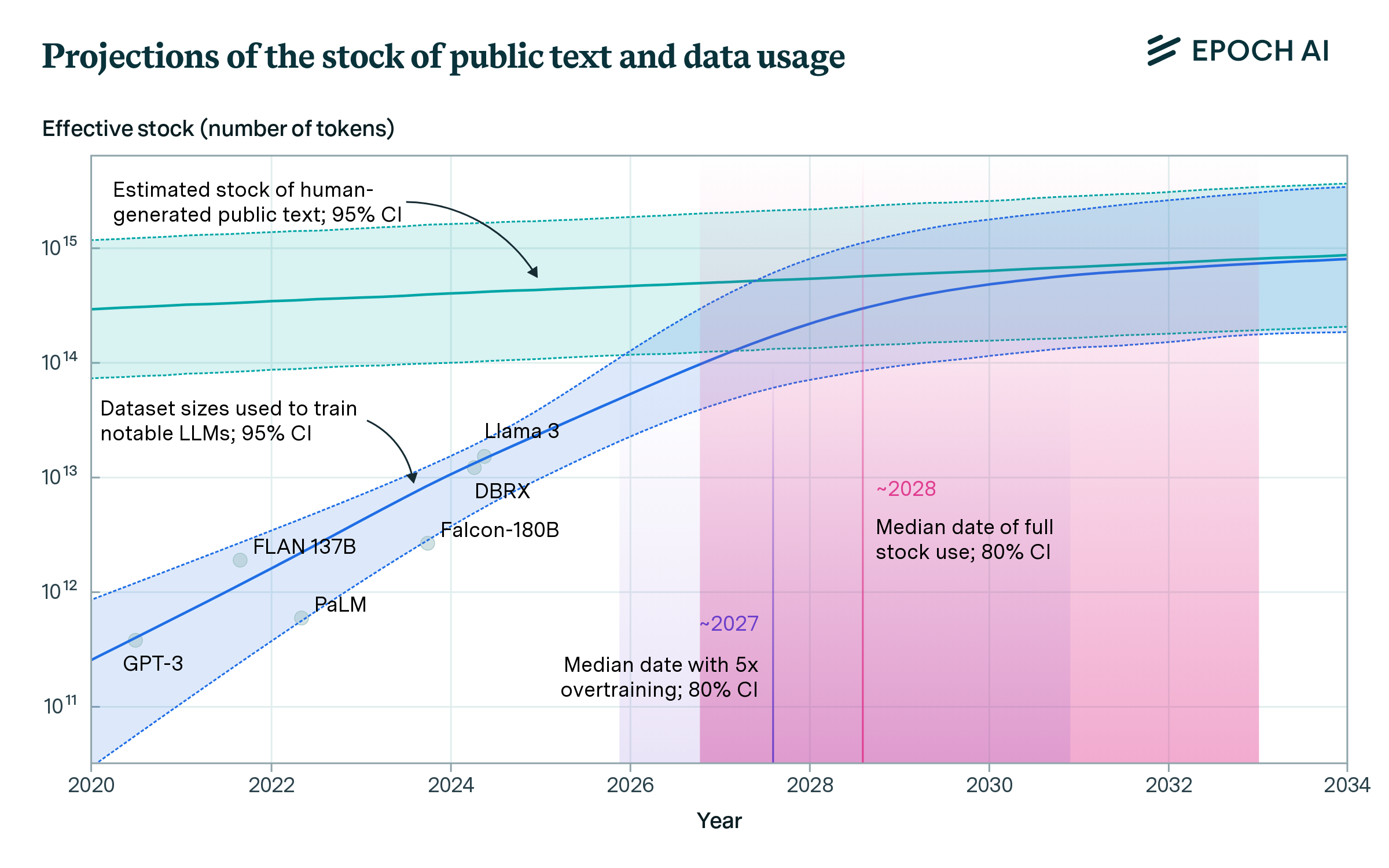
以过度训练(Overtraining)的方式训练模型,即训练数据量超过计算最优缩放定律所规定的模型(每个模型参数对应超过20个token进行训练),则数据用尽的速度会更快。如果模型过度训练 5 倍,那么到 2027 年,数据存量将被完全使用;如果模型过度训练 100 倍,那么到 2025 年,数据存量将被完全使用。作为背景参考,Llama 3-70B 的过度训练倍数为 10 倍。如果训练计算量保持不变,过度训练的模型在推理过程中效率更高(因为它们的参数更少),但代价是数据使用量增加,性能略有下降。
-
- 避免数据耗尽的解决方案
-
训练不足(Undertraining),即继续提高模型参数数量,同时保持其数据集大小不变。训练不足与过度训练相反,它以较低的推理效率和在相同计算水平下略低的性能为代价来减少对数据的需求。虽然训练不足可以带来相当于最多两个额外数量级的计算优化扩展,但预计最终会导致停滞。
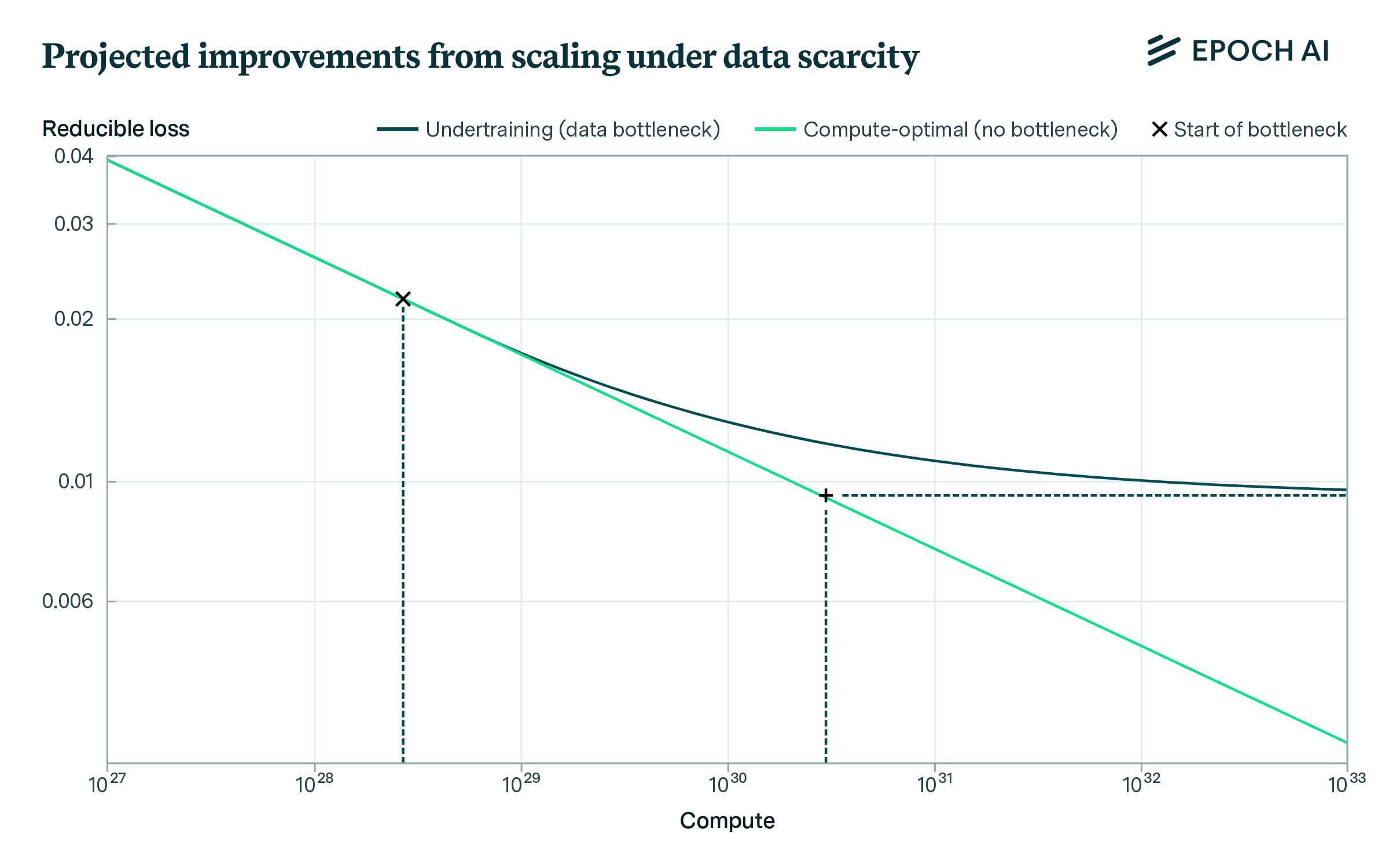
-
使用合成数据(Synthetic data)训练模型。详见章节1.3.3。
-
1.2.3 LLM能通向通用人工智能吗?
- 人类对世界的认知以及行动依靠视觉及其他感官的信息输入,以及对几何关系的理解。单纯依靠语言模型并不足以让AI理解物理世界,并在物理世界中完成任务。
- 未来的LLM系统将会基于海量数据的训练,可能可以回答任何理性人提出的问题,它有庞大的记忆和检索能力,但这是一个不具备创新能力的系统,不能解决新的问题。博士水平的人类能够解决新的问题,这可能是我们对AGI的最终期待。
- LLM并不具备思考能力
- Apple Machine Learning Research: The illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
- 通向具身智能的路径:世界模型
- Yann LeCunn
- 根据访谈,Yann LeCunn对当前以LLM为主流的技术路径持批评态度,认为LLM存在根本局限性,无法真正的通往通用人工智能。
- 要实现AGI需要AI能够理解物理世界规则、有持续的记忆、能够进行推理、能够进行计划。这意味AI需要能够从更多模态的数据中学习,包括视频、触觉等,这其实和多模态模型、具身智能发展的方向是一致的。
- AGI的实现不会是由一小群人,在某个时间点实现的东西,他一定是整个世界的研究人员,在各个方向的探索并持续努力的结果。
- From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning
- Feifei Li
- 认为LLM是有损失压缩,语言是对物理规则的一种更高层次的抽象描述。世界模型才是真正实现AGI的方法,于2024年创立公司World Labs进行世界模型开发。
- World Model可以通过接受2D的图像输入,产出3D的世界建模。
- 世界上的其他动物不一定有语言,但是他们依赖对空间的认知,可以进行行动。”想象一个人,没蒙住了眼睛,而他可以接受语言指令进行行动,这是很困难的行为,但是如果把蒙住眼睛的布拿下来,他就能轻易的进行行动”。人类通过2D的视觉(利用其他感官一起)”在大脑中重建了3D的世界”。
- 更多关于世界模型的内容见章节1.3.4
- Yann LeCunn
- Sam Altman博客
1.2.4 Second Scaling Law
- 也被称为Chinchilla Scaling Law,由DeepMind在2022年3月于”Training Compute-Optimal Large Language Models“中提出。
1.2.5 Test Time Compute
- Run-time Compute (Standard Inference)
- 指从模型中获取推理结果所需的标准、最小计算量,输入数据流经网络各层一次以产生输出。这类推理的主要目标是推理速度和效率,最小化延迟(获取答案所需的时间)并最大化吞吐量(一段时间内可以处理多少个查询)。适用于实时聊天、内容过滤、简单问答等应用。
- Test-time Compute(也叫Inference-time Compute)
- 在推理阶段使用额外计算资源来提高最终输出的质量、准确性和可靠性的策略。主要目标是最大化性能和准确度,即使需要耗费大量的时间和计算,也要获得最佳答案。适用于复杂推理、代码生成、科学分析等应用。Chain of Thought是Test-time Compute思路下的一种具体实现方法。
1.2.6 Software 3.0
- 基于Andrej Karpathy于2025年6月在Y Combinator AI Startup School上的讲话
- Software 1.0 v.s. Software 2.0 v.s. Software 3.0
- Software 1.0是基于代码,人们代码来编写计算机程序;Software 2.0是基于(神经网络的)模型参数,在2.0时代,人们不再直接书写代码,而是通过整理数据集和运行训练算法来“编写”神经网络的参数(Weights);Software 3.0则是通过提示词(Prompt)来“编写”大语言模型任务,就像写代码来编写计算机程序一样,人类的自然语言成为了3.0时代的编程语言。
- HuggingFace in Software 2.0 = Github in Software 1.0
- 大语言模型是新时代的操作系统(Operating System)
- 计算机的操作系统包括闭源的Microsoft Windows, Apple Mac OS以及开源的Linux;大语言模型也有类似的格局如闭源的OpenAI GPT, Google Gemini和开源的Llama等。
-
上下文窗口(Context Window)类似计算机的内存,LLM类似计算机的CPU,浏览器类似于计算机的网络连接。
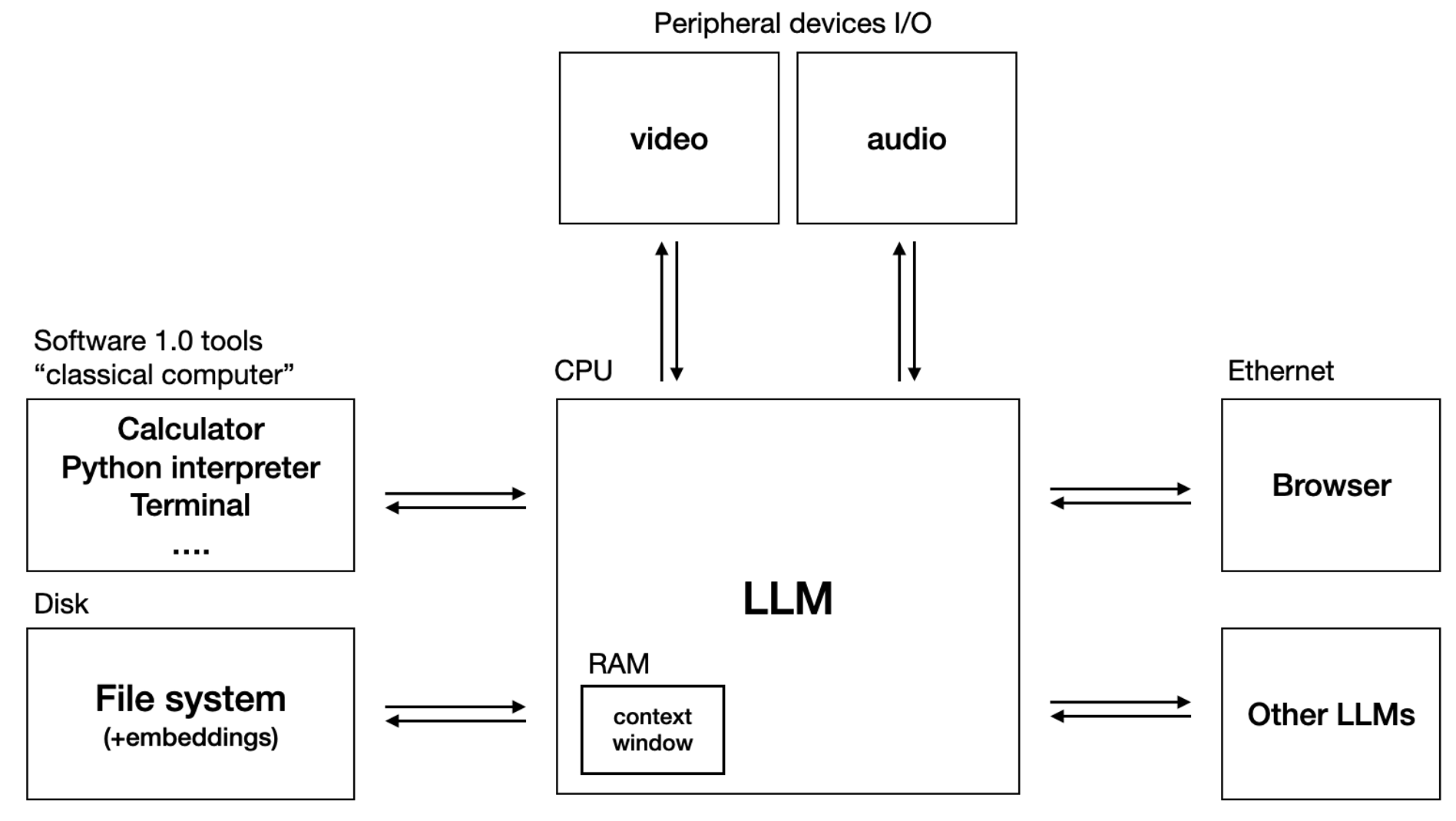
- 正如我们下载计算机软件的时候可以选择在不同操作系统上运行的版本(Windows版、Linux版、Mac OS版),现在的AI应用(如Cursor、Perplexity)也可选择自己的大语言模型内核(Claude、Gemini、GPT o3、DeepSeek等)。
- 计算机的发展历史对大模型发展趋势的启发
- 我们目前正处在类似计算机发展的1950-1970时代,计算机成本很高,操作系统中心化的在云端运行,很多用户共享一个计算机。
- 按照计算机的发展历史,未来会是个人计算机(Personal Computer)的时代,目前苹果的M4 Pro Mac Mini等设备(Apple Silicon的统一内存架构)正在朝这个方向发展,用户可以在家里将开源模型部署在这些小规模的“计算中心”上。
- 与大模型使用语言交互(Chatbot)类似与计算机的操作系统使用命令行终端交互,是一种直接访问的方式,大语言模型的图形交互界面(GUI)还没有被发明。
- 过去的科技扩散趋势一般是政府和企业先发明和使用,再扩散到消费者市场的,比如电力、密码学、计算机、飞机、互联网、GPS等。大语言模型的科技扩散则呈现了一个反向发展的趋势,先从消费者市场受到追捧和广泛接受,政府和企业对于大语言模型的采用是相对更加缓慢的。
- 从心理学的角度理解大语言模型
- LLM是对人类意志(精神、思维,People Spirit)的一种基于概率实现的模仿,目前状态有点类似一种“具有认知障碍的学者”的模仿。
- LLM具备像百科全书一样的广泛知识和记忆,也存在一些短板,比如会产生幻觉、在某些领域存在看似简单却会发生错误的问题(如认为9.11>9.9)。
- LLM的上下文窗口(Context Window)类似于电脑的内存,因此LLM存在“健忘症”,它无法通过形成记忆的方式进行持续性的学习(比如将和用户交互的过程中学到的新知识、技能固化下来存储到参数中)。
- 具有部分自主性的应用(Partial Autonomy App)
- AI应用将结合传统的软件和LLM的交互界面,以Cursor为例,它有一部分传统代码编辑器的交互界面,也有一部分与LLM结合的界面。
- AI应用将负责把上下文组织好(Context Engineering),使需要和相关的背景信息被放置在上下文窗口中,再传递给LLM。
- AI应用将负责协调、调用多个模型,比如用于提取用户提供的文件信息的embedding模型、chat模型等。
- AI应用将会有专门用于该细分领域应用的图形化操作界面(GUI, UIUX)。
- AI应用将有“自主性控制器”(Autonomy Slider),用户可以选择给应用多大的“自主操作权限”,比如在Cursor中用户可以选择是让AI补齐新代码、在一部分代码段落中自主修改、在单个文件中自主修改,或者给予AI整个项目文件夹中所有文件的修改权限。
- 人与 AI应用合作的工作流程中,AI将负责生成,人类负责验证。未来的目标是让人的验证过程变的快速和简便,让AI生成的结果提高其“可采用”率,即成功通过人类验证的概率。
- 为Agent构建的数字基础设施
- 启发:对于用Vibe Coding来写一个网站来说,写代码可以由Agent完成(因此是相对更简单的部分),设置大模型API、部署网站、设置付款方法等等是相对更加繁琐的动作(因为他们目前必须由人来完成)。
- 目前除了为人类获取信息服务的图形界面(GUI)以及为计算机获取信息服务的API,Agent是一种新的数字化信息的消费者/使用者,Agent是计算机但是却像人类一样思考和行动。对很多应用/网页来说,通过API能够访问的信息是相当有限的,远不如图形界面呈现给人类用户的那么丰富。
- 我们可能需要专门为LLM访问设计的网站(如Gitingest、Devin DeepWiki)、说明文档(如Vercel、Stripe)、应用(通过MCP)等,比如说网页可以提供的其内容的Plain Text版本,他们相比JavaScript渲染的版本更便于作为LLM的输入(比如说可能有一些按钮隐藏了网页内的部分内容让Agent无法直接访问,而Plain Text版本则不存在这样的问题)。
1.2.7 The Bitter Lesson
- Richard Sutton在2019年提出的观点
- https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf