1.3 微观层面的AI技术发展趋势
1.3.1 AI Agent
1.3.1.1 Agent的总体架构
- AI Agent是一种能够感知环境、做出决策并采取自主行动以实现特定目标的系统
- AI Agent是一种更智能,需要更少人类介入的AI应用。
-
在我看来,能调用一种/一类工具完成某一个垂直领域任务的AI系统我们可能更习惯于称呼其为AI应用(比如AI教育应用、AI营销应用,但实际上也可以称其为Agent)。能够接受更抽象(高层次)的指令/任务,调用更丰富的工具,解决更广泛且复杂的问题,并能减少人类在系统执行任务时的参与/介入的系统可能是今天比较火热的Agent概念所指代的。下图以一个天气相关的问题的解决流程展示了模型公司和应用/Agent公司的分工,来自该视频。
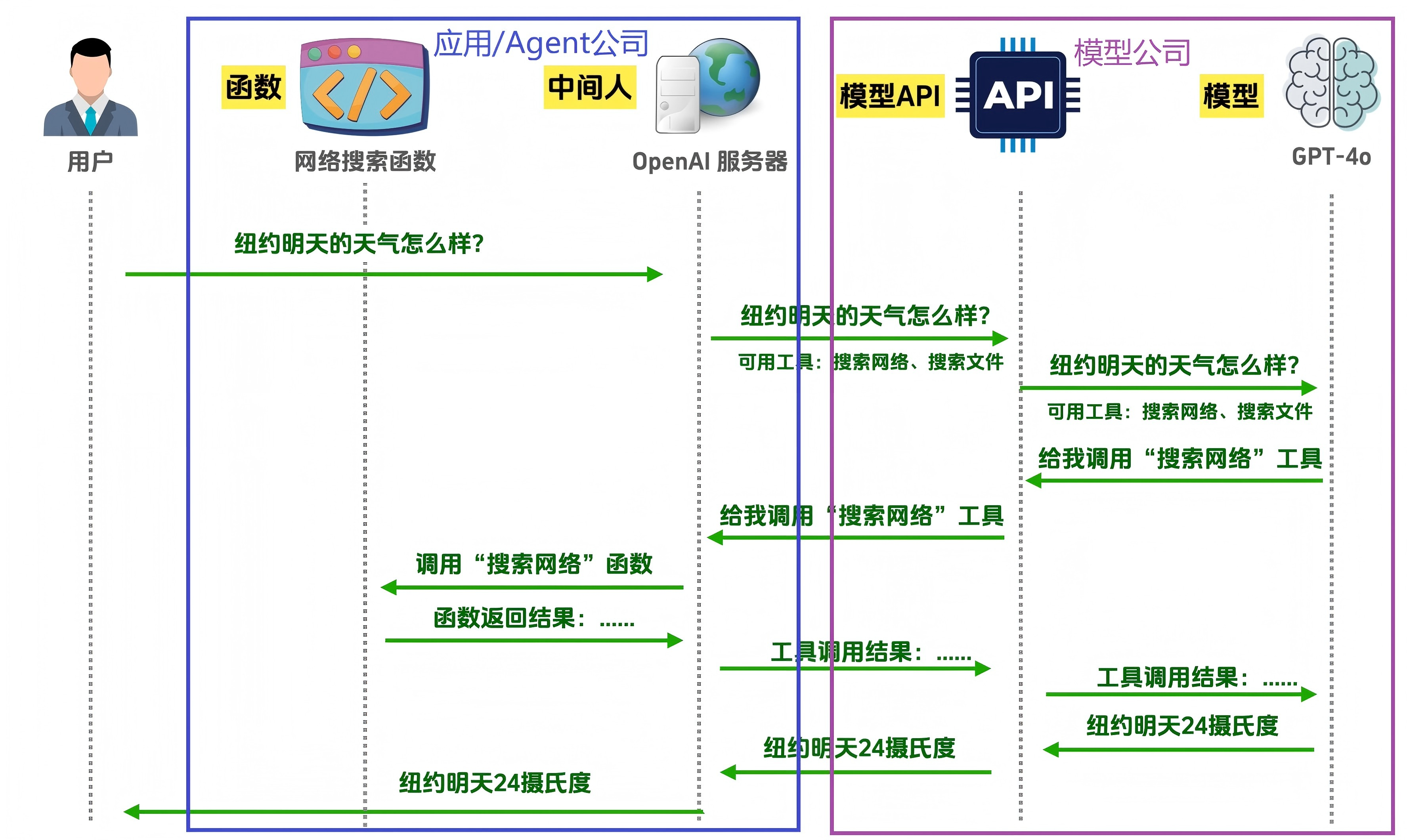
-
研究表明,AI 的 Agent 能力(解决更加复杂和消耗更长时间的任务的能力)在持续不断的提升。这一方面是因为模型可以进行更长时间的思考和复杂任务的拆解(如推理模型),另一方面得益于模型可以调用更多的外部工具来完成更加复杂的任务。
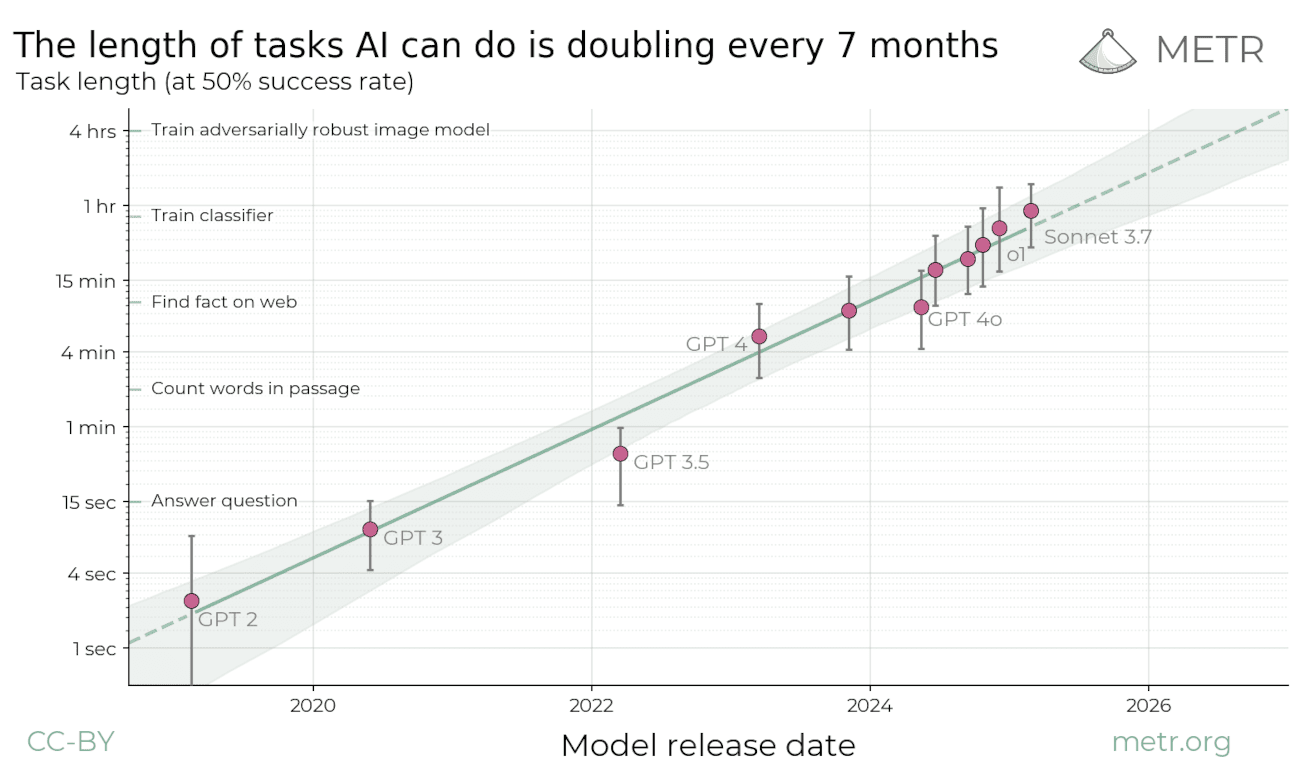
- Agent的总体架构
- 该部分内容参考自Deep Research Agent: A Systematic Examination and Roadmap和LangChainAI Blog
-
目前的Agent一般具有以下架构:使用大语言模型作为认知和推理核心,通过API和浏览器实时的获取外部信息,使用RAG技术将信息整合提供给LLM,通过定制工具包或者标准化交互界面MCP调用外部工具。下图是对Agent系统的示例。
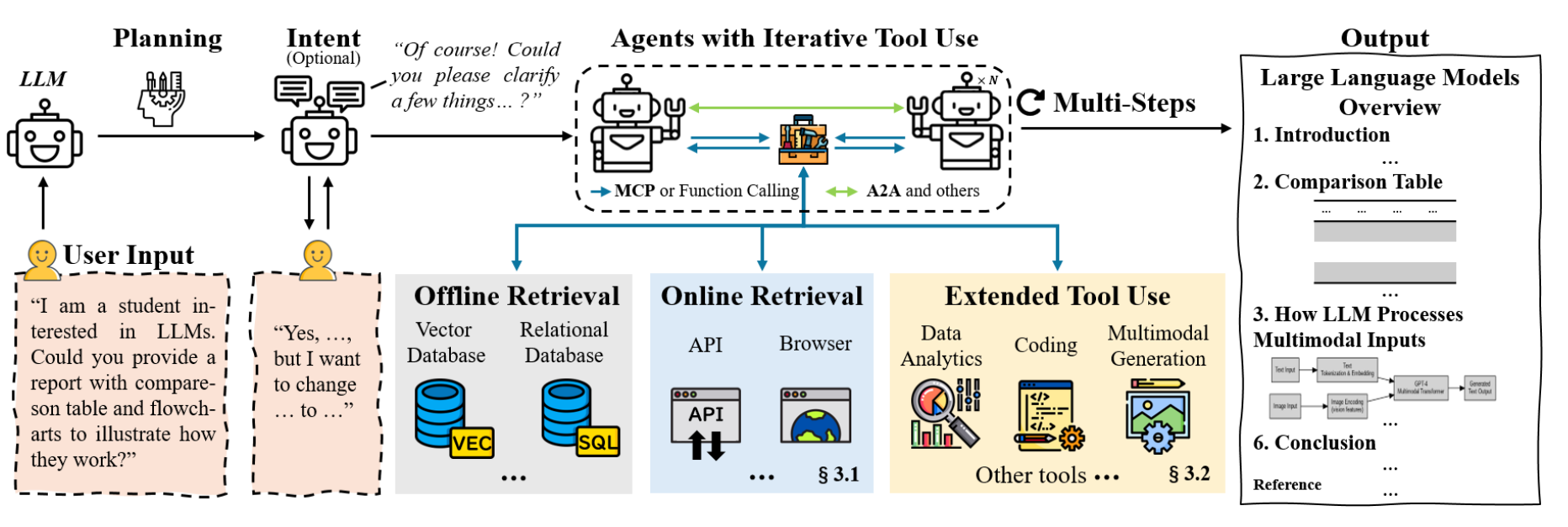
- Agent的搜索引擎
-
Agent一般通过搜索引擎来获取最新的外部信息,而搜索引擎一般可以分为两类,一类是基于API的,一类是基于浏览器(Browser)的。下图展示了两种搜索方式的工作流程。
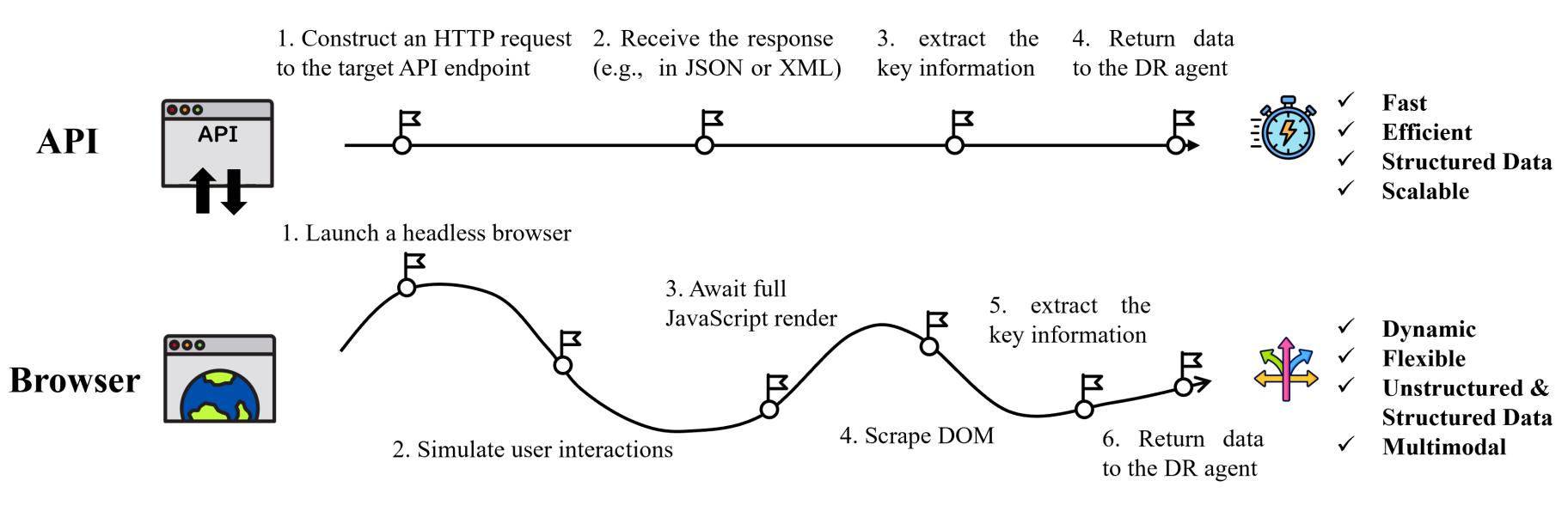
- 基于API的搜索引擎一般是用于获取结构化的数据,比如搜索引擎API,科学数据库API等。
- 通过API获取外部信息的方式能够快速而高效的获取结构化、高访问量的数据源和信息源,比如说Gemini使用了Google Search API和arXiv API,Grok使用了新闻API,Wikipedia API和X API。
- 这些API驱动的方法在访问深度嵌套、存在交互式组件的网页上的内容时(比如说有很多按钮、登陆验证、或者多层网页跳转才能触及的内容)存在障碍,或者某些访问量低的网站开发者就没有写API。
- 基于浏览器的搜索引擎则通过模仿人类与网站的交互方式,获取非结构化的、动态的、多模态的网站信息。
- Manus AI 的浏览代理会为每个对话运行一个沙盒浏览器( Chromium 实例),以编程方式打开的浏览器新标签页、发出搜索查询、点击结果链接、滚动页面直至获取了所需的信息,同时会在必要时填写表单、执行页内 JavaScript 以显示延迟加载的部分,以及下载文件或 PDF 进行本地分析。
- OpenAI, Grok, Gemini 2.5的Deep Research Agent大概率也搭建了类似的架构/功能用于访问互动性网页、多步骤的网页跳转等。
- 基于浏览器互动的搜索方式会导致更大的延迟、资源消耗,也需要处理页面的动态变化和可能的错误。一种API搜索加浏览器搜索的混合架构对Agent是十分有利的。
-
- Agent的扩展应用工具
- 代码编译器(Code Interpreter)
- 代码编辑器帮助模型在进行推理的时候执行代码,让agent具备数据处理、算法验证的能力。
- 数据分析工具(Data Analytics)
- 数据分析工具(包括图表绘制、表格生成和统计分析等)让agent能够统计数据、生成交互式可视化效果并进行定量模型评估,将检索得到的原始数据转化为结构化洞察。
- 多模态信息处理(Multimodal Processing)
- 让agent能接受和生成多模态信息,包括文字、图片、音频、视频等。
- 代码编译器(Code Interpreter)
- Agent的工作流
- 静态工作流(Static Workflows)
- 依靠手动预定义的任务工作流,将研究过程分解为连续的子任务,如构思-实验-报告。静态工作流结构清晰,易于实现,但其泛化能力有限,需要为每个不同的任务专门定制工作流程。
- 动态工作流(Dynamic Workflows)
- 允许agent根据迭代反馈和不断变化的环境动态地重新调整任务。
- 根据任务计划的方式,可以分为以下三种:
- Planning-Only:直接根据初始用户提示生成任务计划,不会主动向用户要求进一步的澄清。采取这种做法的产品包括Grok,Manus。
- Intent-to-Planning:在规划之前,通过有针对性的问题主动和用户确认意图,然后根据确认后的用户输入生成定制的任务序列。采取这种做法的产品是OpenAI Deep Research。
- Unified Intent-Planning:以上两种方法的结合,根据用户的初始提示词生成初步计划,并与用户互动以确认或修改拟定的计划。采取这种做法的产品是Google的Gemini Deep Research。
- 根据Agent的数量,可以分为以下两种:
- 单智能体:由单个推理模型完成计划、工具调用、执行等任务,并进行推理、行动和反思的迭代循环。其优点在于单智能体系统能够在整个工作流程中实现直接的端到端强化学习 (RL) 优化。
- 多智能体:利用多个专用(于某项任务)的agent协作。这些系统通常采用分层或集中式规划机制,其中有一个负责协调的agent根据实时反馈重新规划和分配子任务。代表性框架包括 OpenManus 和 Manus,均采用分层的“规划器-工具调用器”的架构。多智能体系统擅长处理复杂、可并行的任务,但因为其需要协调多个独立的agent导致了系统复杂性很高,很难进行端到端强化学习 (RL) 优化。
- 静态工作流(Static Workflows)
- Agent的记忆管理
- Agent通常会执行大量的多轮检索,生成数十万个(甚至数百万个)token。LLM 有限的上下文窗口长度制约着涉及极长上下文的任务。Agent系统采取了以下三种方法来处理记忆管理问题:
- 扩大上下文窗口的长度:最直接的方法,主要是Google Gemini选择了该路径,其支持最长达到1百万个token的上下文窗口长度。这种方法通常会产生较高的计算成本,并在实际部署中导致资源利用效率低下。
- 压缩中间推理步骤的信息:在涉及多个任务的流程中,将前置任务的结果进行总结,再作为给下一个阶段任务的输入。这种方法的一个缺点是可能丢失详细信息,这可能会影响后续推理的准确性。
- 使用模型外部的结构化信息存储工具存储中间步骤的结果和历史交互数据:Manus,OpenManus等项目使用了这样的外部文件存储结构,其他的一些方案使用了向量化数据库来进行记忆存储。
- Agent通常会执行大量的多轮检索,生成数十万个(甚至数百万个)token。LLM 有限的上下文窗口长度制约着涉及极长上下文的任务。Agent系统采取了以下三种方法来处理记忆管理问题:
1.3.1.2 如何搭建一个Agent
-
Agent路线1:能调用专为AI设计的外部工具(API)的AI模型
-
大模型本身不具备调用外部工具的能力 ,而且其知识仅限于模型训练时间点之前数据集里的信息。当用户询问模型某地明天的天气如何时,模型需要使用外部天气查询工具,一般是通过服务器调用API并将结果和用户的问题一起传输给模型,模型使用这些信息完成回答,最后再将结果返回给用户。
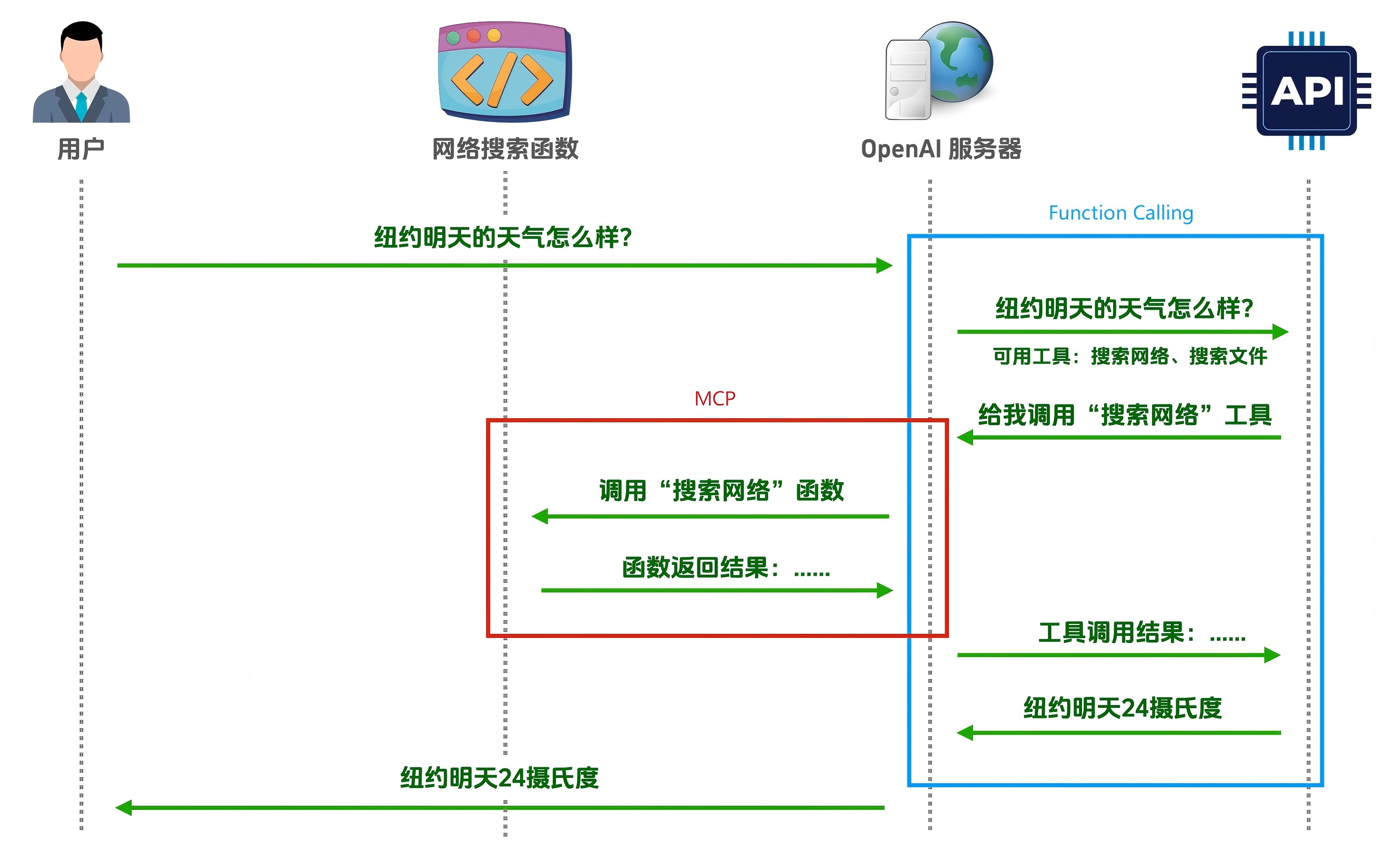
- ChatGPT Plugin
- OpenAI在2023年3月发布了ChatGPT插件系统,让模型可以使用第三方的工具,其中最重要的工具就是浏览器和搜索引擎,这让模型可以访问网站、进行搜索以获取最新的信息,这个其中就使用了RAG技术。
-
- OpenAI在2023年6月在博客中发布了Function Calling的更新,使得OpenAI的模型具备了更加方便的调用外部工具、获取外部数据的能力。在Function Calling功能发布之前,使用GPT API开发应用的开发者需要用prompt告诉模型要如何调用外部的工具,每一种工具可能都有不同的函数格式,如果使用的工具数量比较多,这会是一个非常繁杂的过程(例如告诉模型在需要调用工具时的函数怎么写),而且模型有些时候会发生错误,其输出的工具调用函数不一定正确。此后开发者需要将模型生成的外部工具调用指令在服务器上运行,再将外部工具的查询结果和用户的输入一起传输给模型。
-
Function Calling功能通过使流程原生化和结构化解决了这个问题。模型不再输出可能有错误的字符串,而是输出一个保证有效的格式化、模板化的结果,结果与开发人员定义的模式能够精确匹配。这消除了通过文本解析生成外部工具调用代码的的不可靠性,使模型与外部工具之间的连接更加稳定且更易于实现。Function Calling的工作示意图如下图所示,图中的Developer就是AI应用/Agent的服务器。
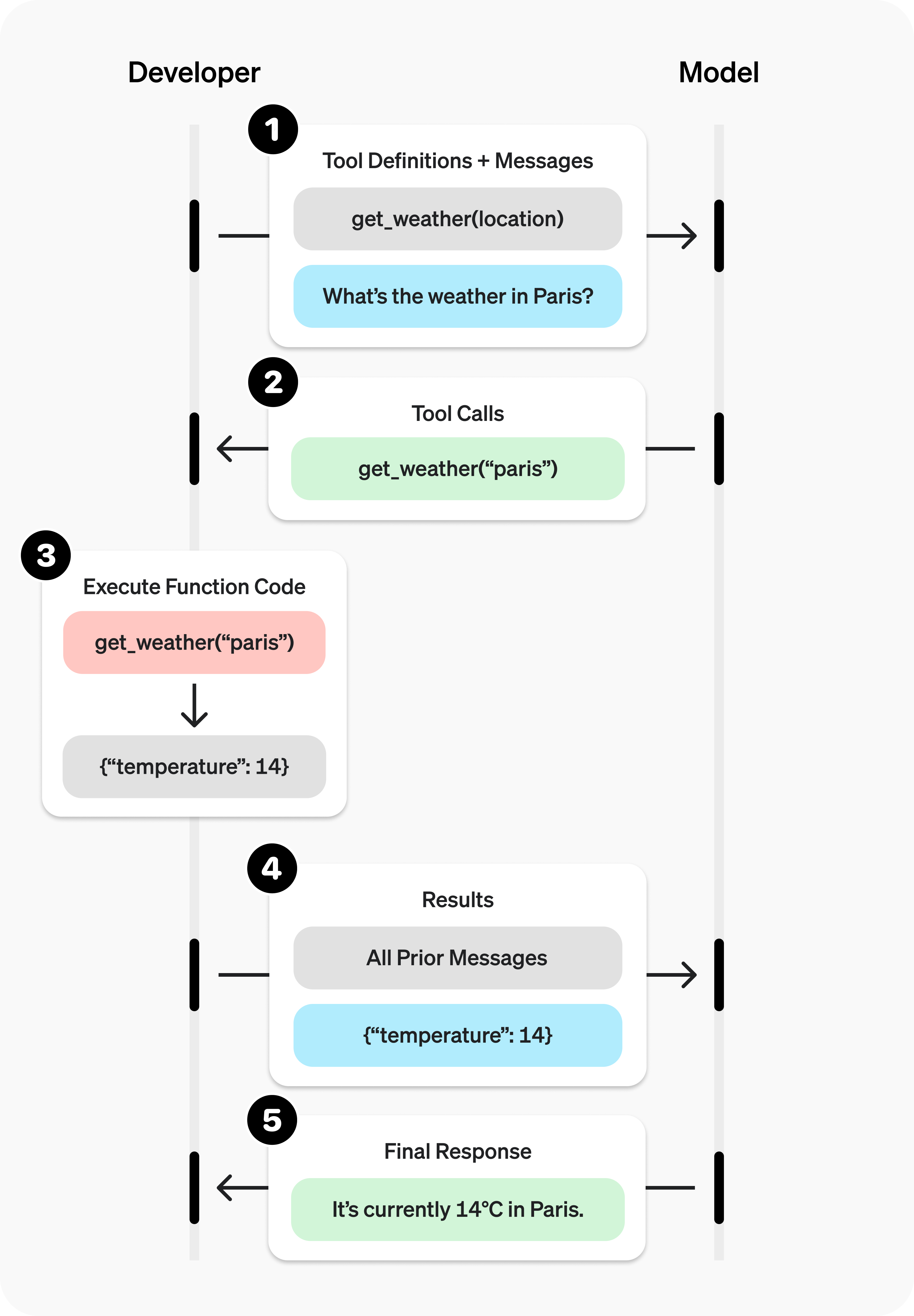
- Model Context Protocol (MCP)
- 在MCP出现之前,应用服务器在调用不同的外部工具的时候面临不同的API标准/格式。因此对每一个新的工具,开发团队都需要重新有针对性的写代码才能让应用服务器具备调用的能力,这导致了很多重复开发,高额的维护成本等等,严重限制了应用服务器在调用更多工具方面的可扩展性。
- Anthropic在2024年11月在博客中提出了MCP。Function Calling是作用于模型和应用服务器之间(如ChatGPT的服务器)的,而MCP是作用于应用服务器和第三方工具之间的一种交互标准。直白的来说,MCP就像是一个翻译器,不同的应用在说着不同的语言,以前LLM每次想和一个新的应用交流,程序员都要教会他一门新的语言,这个成本很高,现在有了MCP这个翻译器,比如说把每个应用说的语言都翻译成英语,那现在LLM就只需要学一种语言就可以(通过MCP的翻译)和其他所有的应用交流了。MCP的服务器端就是负责把应用原生语言和英语互相翻译的工具,由应用的开发者来负责书写。
- MCP 是一个开放协议,它规范了应用程序向 LLM 提供上下文的方式。MCP 就像 AI 应用程序的 USB-C 端口一样。正如 USB-C 提供了一种标准化的方式将电脑连接到各种外围设备和配件一样,MCP 也提供了一种标准化的方式将 AI 模型连接到不同的数据源和工具。
- MCP 主机(Host):需要通过 MCP 访问数据的程序,例如 Claude Desktop、IDE 或 AI应用
- MCP 客户端(Client):与服务器保持一对一连接的协议客户端
- MCP 服务器(Server):轻量级程序,每个程序都通过标准化的模型上下文协议 (MCP) 公开特定功能
- 本地数据源:MCP 服务器可以安全访问的计算机文件、数据库和服务
- 远程服务:MCP 服务器可以通过互联网(例如通过 API)连接到的外部系统
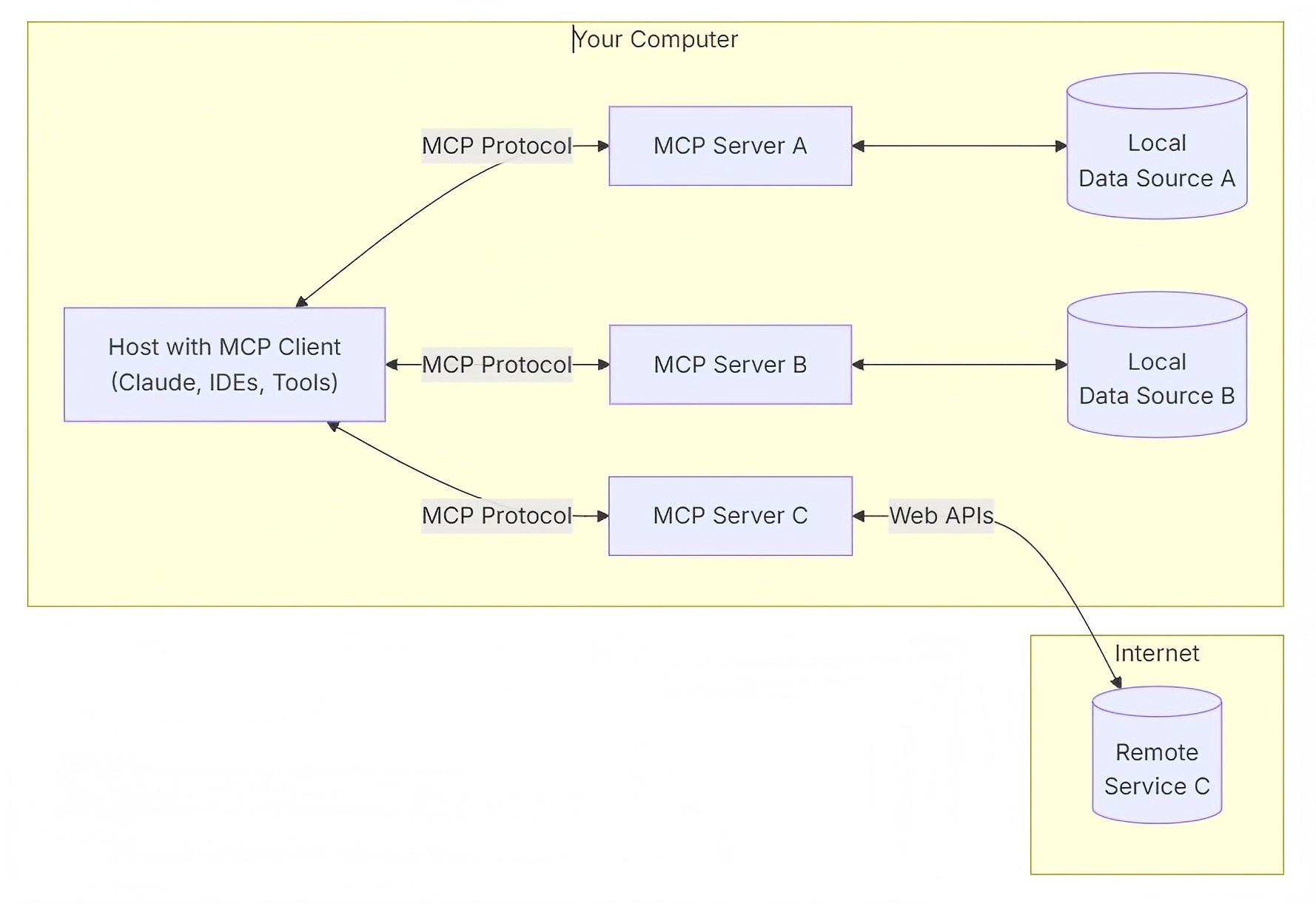
-
- OpenAI于2025年7月推出了Connectors in ChatGPT功能,允许ChatGPT连接第三方软件和服务(比如Google Drive, GitHub, SharePoint)以帮助模型访问用户自己的数据源。
- Connectors有以下几种类型:
- Chat Search Connector:快速寻找到第三方软件(如Google Drive)中存储的相关文件,提取信息并用于回答生成。
- Deep Research Connector:主要用于更复杂的Deep Research任务中,同样用于获取用户信息生成报告。
- Synced Connector:将重要/常用的第三方软件中存储的内容提前/预先载入到ChatGPT的“记忆”(Context)里,这样可以减少访问数据所需的时间。
- Custom Connectors:用户可以添加遵循MCP规范的自定义Connector来连接到自定义第三方应用程序和内部数据源。
-
-
Agent路线2:能够像人类一样使用电脑的AI模型
- Anthropic Computer Use
- Anthropic于2024年10月提出了Computer Use功能。其思路和上文提到的让模型通过API访问专门为模型设计的外部工具的思路不同(”让工具适应模型”),该方法旨在让模型”像人类一样使用电脑”(”让模型适应工具”),进行如查看屏幕、移动光标、单击按钮和输入文本操作。模型不需要通过定制工具进行交互,而是能够按照指示使用任何软件。
- Computer Use让模型具备了操作计算机所需要查看和解读计算机屏幕图像的能力。模型还需要推理如何以及何时根据屏幕上的内容执行特定操作。模型会查看用户可见内容的屏幕截图,然后计算需要垂直或水平移动光标多少像素从而点击正确的位置。
- Browser Use
- GitHub上的一个开源项目,是一种帮助AI模型访问浏览器的工具。后来成立了公司,收取费用提供API和云服务(即可以在Browser Use提供的服务器上运行模型和浏览器访问工具)。
- 将视觉理解与 HTML 结构提取相结合,实现全面的 Web 交互;自动处理多个浏览器页面,以实现复杂的工作流程和并行处理;允许添加自定义操作,如保存到文件、数据库操作、通知或人工输入处理。
- OpenManus
- GitHub上的一个开源项目,在Manus发布后3小时内发布,由于Manus刚发布的一段时间内需要邀请码才能访问,OpenManus声称其能实现类似的功能而迅速获得了关注。其是基于Anthropic Compute Use及Browser Use的更高层次的集成和开发。
- OpenDia
- Github上的开源项目,实现Dia Browser类似功能的项目。
- Anthropic Computer Use
1.3.1.3 Agentic AI
1.3.1.4 Coding Agent
- Coding的产业应用场景与Context Engineering
- 在产业界,写代码的场景分为两种,一种是从零开始搭建新项目,另一种是维护已有代码库并且开发新功能。在这种情境下,Agent要能理解已有的代码(即上下文,或者叫背景知识,Context),并且确保更改和新增的功能不会与已有代码发生冲突。
- 特别是维护已有代码库的场景中,上下文(Context)可能特别长(比如大型项目的代码行数可能达到了数十万行),超出了LLM能接受的Context Window(目前最大的Context Window应该是Gemini 2.5 Pro的一百万token),因此在处理大规模的编程项目的时候可能存在困难。这意味着大模型目前不能把整个项目的代码一次性读取进去,而是需要使用者人为对代码和任务进行拆分,把相关的和重要的上下文筛选和提供给Agent。这个过程被称为Context Engineering(上下文工程)或者叫“记忆管理”。
- Coding Agent与程序员的合作分工
- 程序员负责定义需求、提供背景信息、设定限制条件、验收代码。Agent负责写代码、写测试用例。
- 可能的流程是“人提需求->Agent写代码->代码出Bug->让Agent修Bug->让Agent写测试->人验收”如此循环往复。
- 修改代码和bug的对话会占据模型的记忆空间,污染上下文,以至于对话轮数多了之后模型可能会忘记最开始的需求。其中一个待解决的痛点是想办法让模型自行将过往对话记忆下来(比如说为什么出Bug,和已有代码存在什么不兼容的地方等),而不是重新提出需求。
- Coding Agent公司的价值
- 大模型提供了基础的推理能力和编程能力,要实现真正的“可脱手”Coding Agent,相关公司需要将目前仍由人类完成的工作自动化:将大问题拆解成AI可以解决的小任务、管理好上下文和记忆、将小任务分给具备合适能力的模型、处理好“生成代码-验证(测试)代码”的用户交互流程。
- 正如计算机系统里,除了计算核心CPU(类比现在的大模型)还需要有内存(Memory)管理、输入输出(I/O)管理等等,Agent系统里这些功能也需要公司来实现。
- Coding Agent带来的变化与机会
- Coding Agent提高了高级别程序员的工作效率:高级程序员根据过往项目经验和相关需求搭架构,Agent自动处理好基础编程任务,高级别程序员可以减少在“带新人”上花费的时间和沟通成本,只需要教一遍,就可以有多个Agent同时干活。因此业界对入门级别程序员的需求可能下降,同时入门级别程序员的成长更加困难了,因为高级程序员不愿意再花那么多时间教新人了。
- 在这次的Cursor分享会上,很多嘉宾和参会的人并不是编程背景的,很多是产品岗、设计岗的人,他们并不会编程,但是通过Cursor这样的工具,他们可以很快完成产品原型的构建和应用的开发。
1.3.1.5 Agent产品分析
- Coding Agent
-
对比GitHub Copilot、Cursor及Manus在制作网站方面的使用体验
GitHub Copilot Cursor Manus 定位 Coding Copilot,面向程序员 Coding Agent,面向程序员 General Agent,面向大众的消费级产品,具有案头研究和编程能力 作用范围 最低,单个代码文件内 中等,整个项目文件夹里的所有文件 最高,包括虚拟机上运行的浏览器、代码编译器、命令行工具、文件系统等 作用位置 用户编程所用的电脑上 用户编程所用的电脑上 云端虚拟机 指令抽象度 最低,需要给出非常具体和清晰的指令,比如某个函数的输入是什么、输出是什么、需要实现什么功能。 中等,描述具体需要实现哪些功能。比如说需要一个悬浮的目录用于展现网页内容提纲,并且点击后可以跳转到相关内容等。 最高,站在网站整体的角度提出需要实现的目标。如,从各个新闻网站中抓取并展示当日的最新新闻。 专业知识需求 最高,需要了解网站搭建的架构、每个文件需要写什么功能和函数。 中等,需要大致了解网站搭建的架构、命令行工具的使用方法;当出现bug时,需要用户主动和Cursor提出问题,Cursor会帮助修改代码和给出建议,如果Cursor解决不了问题,需要用户自己处理。 最低,基本不需要有编程知识,就能够自己实现、测试、部署网站,简单的网站基本没有问题(暂时没遇到需要处理bug的情况,也有可能其能够自主修缮bug),复杂的网站实现没有测试过。
-
- Manus
- 以下内容主要来自推送文章和Manus创始人采访
- Manus的特点
- 相比Cursor,Manus面向更广阔的”编程小白”群体,是一个消费级的产品
- Manus在云上部署了虚拟机,所有的程序在虚拟机上自动执行(虚拟机是一个虚拟隔离的完整系统,模型乱操作搞坏了也没关系,直接将虚拟机重置即可),甚至可以说虚拟机本身就是为了让Manus更好的编写代码而存在的,一般的案头工作是不太会“搞坏系统”的。
- Manus Agent的形式是虚拟机+浏览器+模型写代码调用API+自行多轮迭代运行/试错,可以自助拆解任务,一步一步执行,实时汇报进度
- Manus也是基于Claude Sonnet 3.5等模型的长程规划能力和逐步解决问题的能力才能实现较为令人满意的效果
- 从Monica到Manus
- 在 Manus 之前,肖弘团队的AI 浏览器插件 Monica 更像是「功能机」——添加功能就是增加管线。每诞生一个新热点,可能都意味着一套新产品的开发逻辑、也是一个全新的项目。
- Manus 有了一个通用的底子,更像是一个「智能机」了——可以在这个通用的底座上,更高效地创造出层出不穷的好应用。可以不需要大量招聘工程师、建无数多项目条线,而是去观察用户在哪些场景下用得好,以做「减法」,优化这些被验证的路径,让交付结果更好更确定,让运行效率更高。
- 先发红利
- 先行者验证了市场需求和技术可行性,让后来者更容易复现类似的产品。比如 OpenAI 推出 ChatGPT 后,大模型创业门槛大幅下降,各家迅速跟进。但与此同时,壁垒的「宽度」却增加了——先行者积累的用户、资本和生态优势,让后来者除非实现「跨代创新」,否则很难真正颠覆其地位。特斯拉也是一个典型案例:它率先突破电动车市场后,虽然新势力崛起更快,但至今仍难以撼动其行业主导权。
- 用户的心智,以及大模型时代带来的用户 Prompt 习惯、个性化的数据、工作流和生活流的锁定,这些都是在先发优势上很容易获得,但是长期来看会越来越贵才能去获得的资源。
- 通用AI产品
- 其实观察下高用户量的「AI 通用产品」,比如无论是 ChatGPT 还是国内的 DeepSeek 上的用户问答需求,就可以看出来绝大部分需求没有那么深层和复杂。在 Agent 领域也是一样,其实没有那么多用户脑子里有那么高频的复杂任务,很可能是 80% 的用户的 80% 最常用的任务,在一定程度上是可以收敛的。而率先把这里两个 80% 叠加的任务都能交付好 80%,你就是他们心中的「通用 Agent」。这个需求收敛模型带来的实际震惊结果是只要覆盖半数核心场景即可触发「通用感」了。
- 对于通用 AI 产品,只要有资源,唯一正确的策略,就是在前面提到的「需求收敛模型」上,用不断的创新成果和更好的交付,形成对用户的卷入,只有用户是壁垒,是不断增值的资产。
- 套壳产品
- 做套壳产品的一种思路是先猜测未来会有什么应用,先把应用(壳)做好。当下时间点的模型能力未必能跟的上,但等到足够强大的模型出现了,这个产品可能就会有一个飞跃。
- “选择一个垂直领域,那个领域的业务流程应该有一点复杂,今天的模型还不能很好的解决,但是你预测模型的魔法一定会到来,先把业务流程做好,等着模型变强就好了”。
- 以Cursor为例,这个产品是2023年2月创立的,直到2024年7-8月火起来的,是依靠Anthropic的Claude Sonnet 3.5作为核心,模型能力的提升带来了产品使用体验和实用性的大幅提升。
- 和模型厂做好差异化
- 基于API应用于垂直领域的应用模型厂不会做,脏活累活模型厂不会做,有一些产品模型厂可能以后会做,有一定的窗口期,如果市场上有玩家做的很好,模型厂可能就会选择放弃或者直接收购。
- 线性逻辑推导的思路下,大厂有绝对优势,但是在博弈的思考路径下,环境会因为其他玩家的出现和他们所做的事情受到影响(e.g. DeepSeek的出现导致了OpenAI开始考虑要不要开源,这在之前是很难想象的)
1.3.1.6 多智能体系统
- Agent-to-Agent多智能体交互协议
- Google在2025年4月发布了Agent2Agent(A2A)协议,旨在促进多agent协作。在该协议下,来自不同厂商和基于不同模型架构的agent可以发现同伴、委派职责,并以平等的参与者身份协作管理复杂任务。
- AI Agent vs Agentic AI:推送文章
- LangChain
[!TIP] Todo
- Agent公司都解决了什么问题,为什么可以用AI做一遍自动化的工具?
- Monica vs Manus
- Cursor - Vibe Coding
- Devin
- Claude Code
- LangChain
- Coze
- GenSpark
- 多Agent合作
- 斯坦福AI小镇,”Generative Agents: Interactive Simulacra of Human Behavior”
- ICML 2025论文,”Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems“,在多Agent系统中识别出错的是谁
- Collaborative multi-agent reinforcement learning (MARL)
1.3.2 机器人与具身智能
1.3.2.1 传统机器人控制
- 大模型之前传统的大脑和小脑架构
- “感知-规划-控制”的分层架构
- 任务分配层、行为决策层、运动规划层和运动控制层
- 波士顿机器人
- 高泛化性、高鲁棒性和高泛化性是具身智能领域的“不可达三角”
- 上肢和下肢控制的研究是“分开的”
- 上肢控制(Manipulation):银河通用
- 下肢控制(Locomotion):波士顿机器人、宇树科技
1.3.2.2 Vision Language Model
- 具身智能是一种可以和物理环境进行互动的AI Agent
- 物理图灵测试(Physical Turing Task)
- 机器人在与物理世界的交互中做出了和人类一样的结果。比如将一个混乱的房屋整理的井井有条,而我们无法分辨这个效果是人类所做还是机器人所做。
- Physical API
-
未来具身智能也会像目前的AI一样,人们可以通过API来调用他们,作为各类具身智能应用的底层模型。
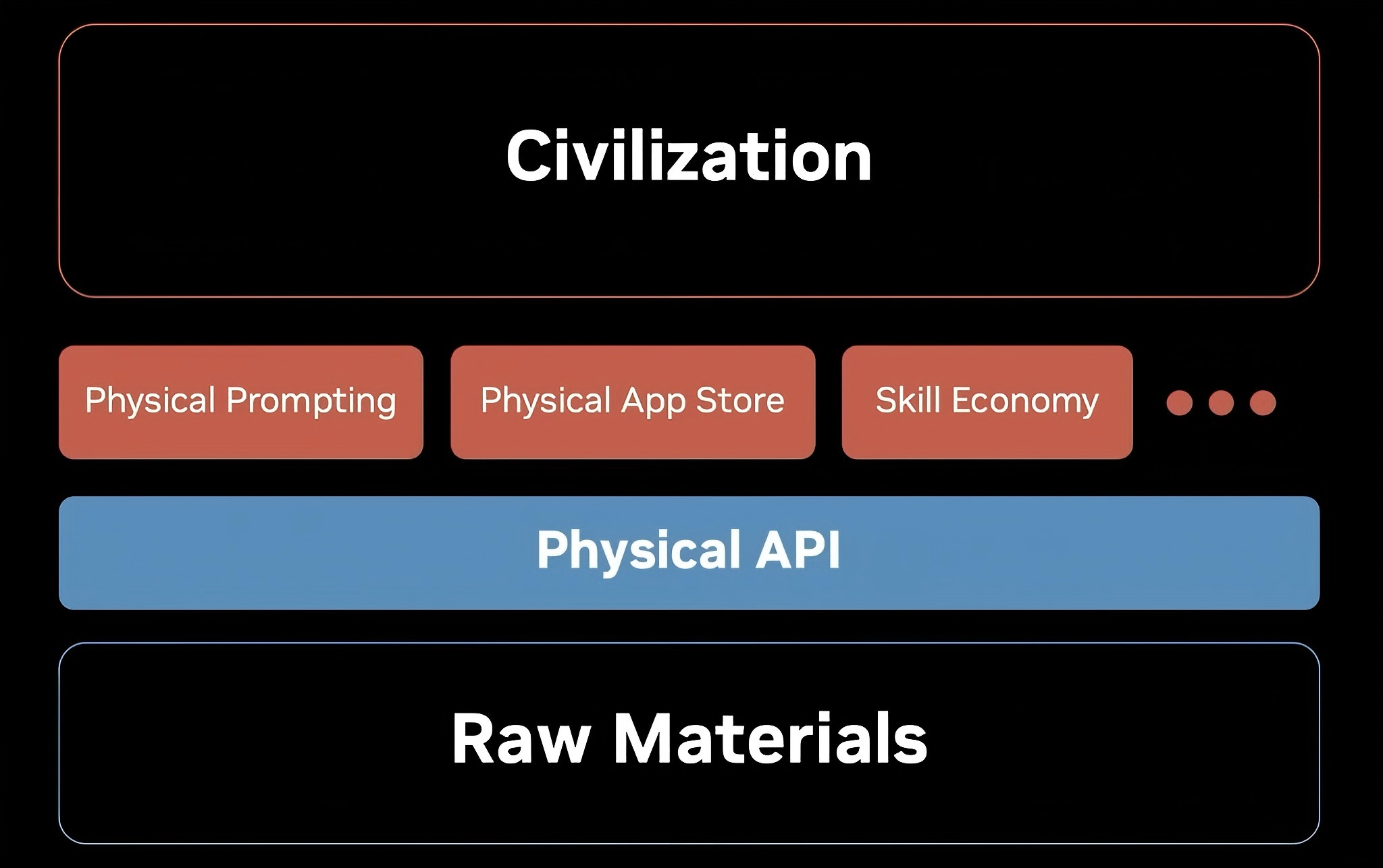
-
- 物理图灵测试(Physical Turing Task)
- Vision-Language-Action (VLA) Model
- Figure AI Helix
-
大脑(慢系统)+小脑(快系统):Helix的大脑被称为System 2,小脑被称为System 1。其中大脑是参数更多的大模型,因而推理速度较慢,输出的频率为7-9Hz,而小脑的参数更少,推理速度更快,输出频率为200Hz。
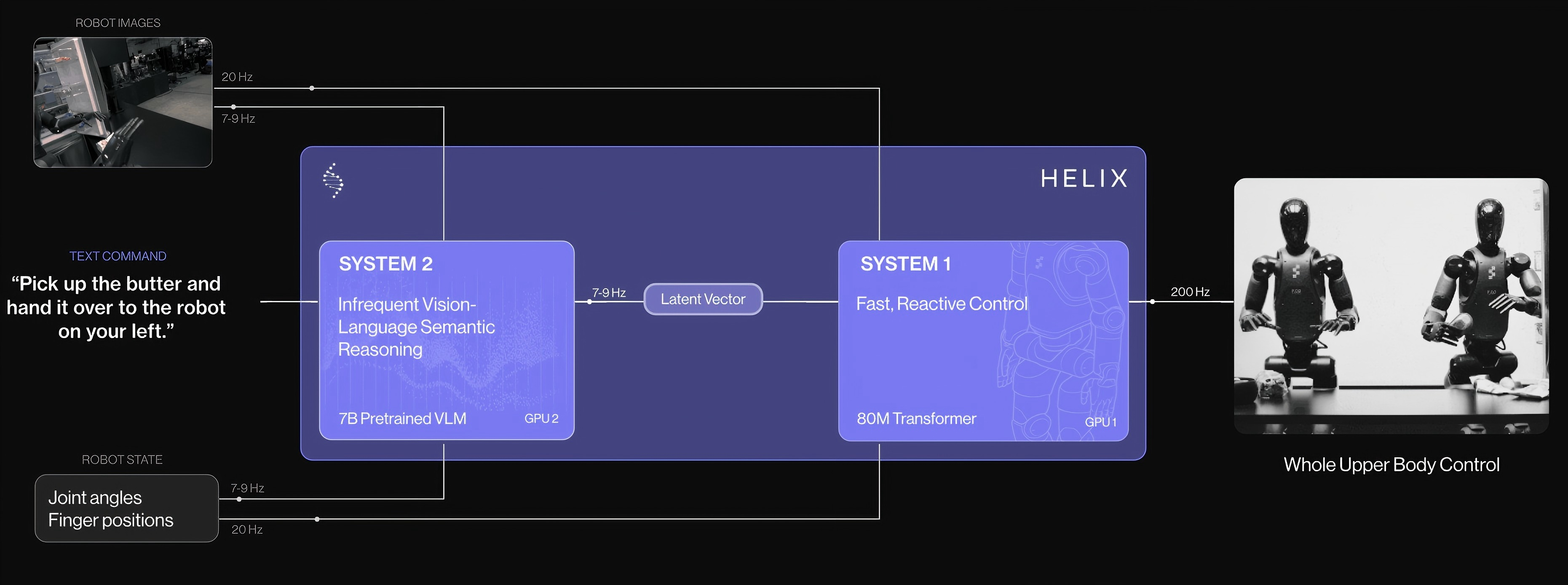
- 潜在向量(Latent Vector):连接大脑和小脑的数据结构是潜在向量,信息通过潜在向量从大脑想小脑传输,潜在向量是人类不可直接理解的数字(向量)表示形式。梯度可以通过潜在向量从 S1 反向传播到 S2,整个大脑+小脑的系统是端到端的
- 能够识别、抓取、放置从未在训练中见过的物品,展现出对各种形状、尺寸和材质的物品稳健的泛化能力
-
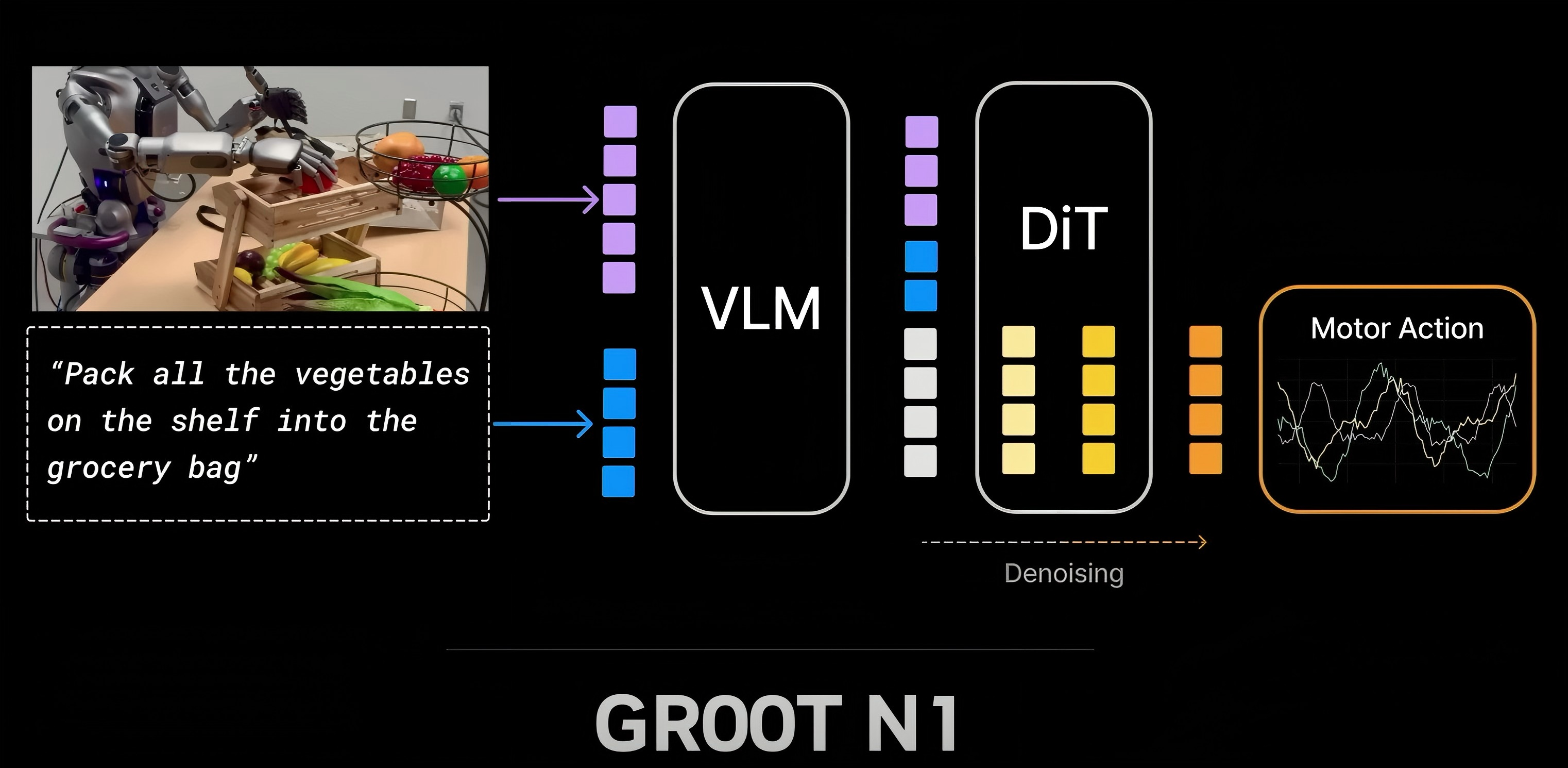
- Nvidia GROOT N1
-
输入视频和语言指令,输出电机关节指令。可以实现多机器人协作。
-
-
Google Gemini Robotics
-
Physical Intelligence
- Tesla
- Figure AI Helix
- 模仿学习(Imitation Learning)
- 遥操作(Teleoperation)
- A Survey on Vision-Language-Action Models for Embodied AI
1.3.2.3 具身智能训练数据获取
- 具身智能的训练数据获取
- Figure AI
- 自行收集了多机器人数据集,包含各种遥控操作的行为,总计约 500 小时
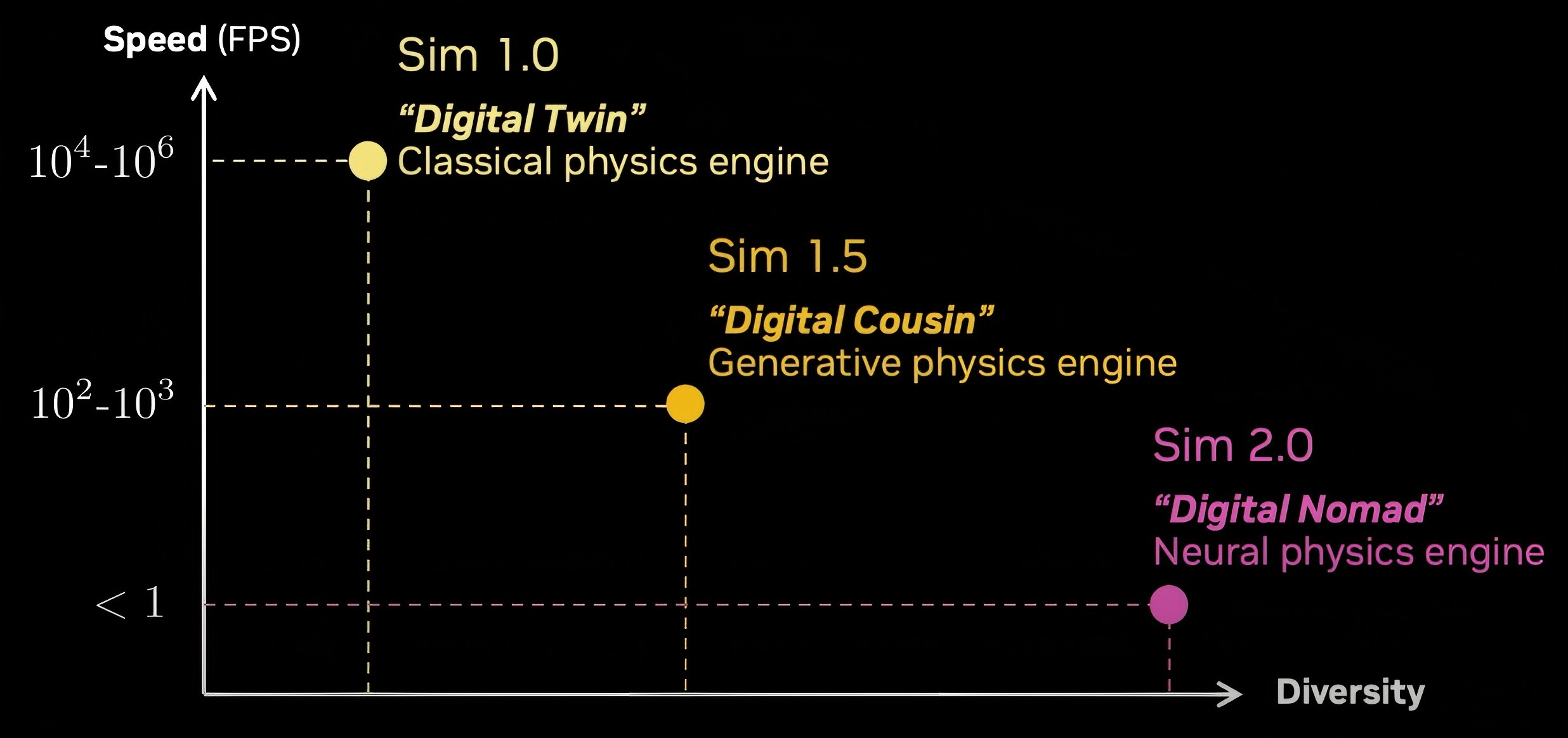
- 英伟达的具身智能发展路线:Simulation 1.0 - Simulation 2.0
-
基于Nvidia机器人业务负责人Jim Fan于2025年5月在红杉资本AI Ascent 2025上的分享
- 真实机器人数据
-
由人类遥控现实世界中的机器人进行操作(Teleoperation)完成任务,并收集机器人的关节位置随时间变化的数据(关节控制信号)。
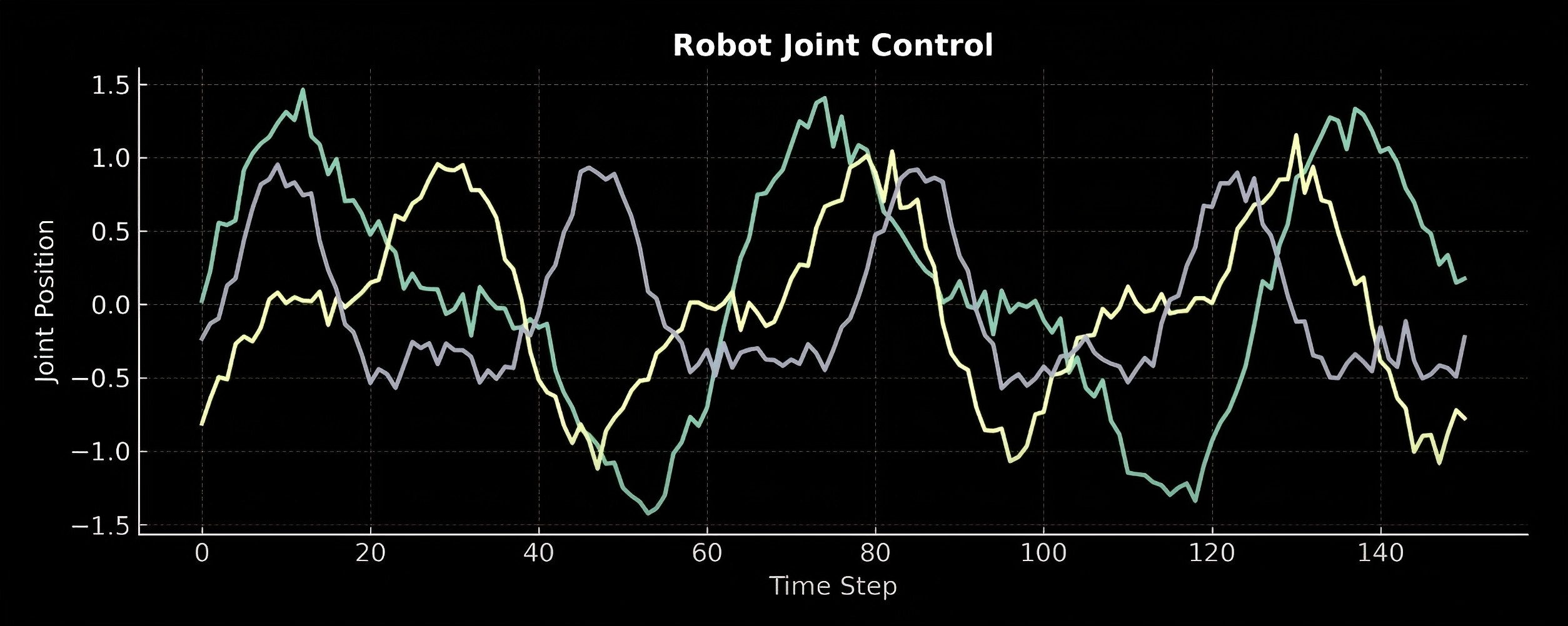
- 市面上没有现成的数据,需要由操作员使用头戴式VR设备,由VR设备识别操作员的手部姿势并将信号传递给机器人。
- 这类数据的收集非常昂贵,且效率非常有限(最高效率是24小时/机器人/天),依赖于操作员的“人力供给”。
-
- Simulation 1.0:基于传统物理引擎(Classical Physics Engine)的数字孪生(Digital Twin)仿真
- 需要人工构建一个机器人的数字孪生(即对真实世界的机器人、灵巧手等的数字复刻)和虚拟环境。算法在仿真环境中训练,并在现实世界中测试训练效果。这一方法在Nvidia的论文”Eureka: Human-Level Reward Design via Coding Large Language Models“中使用。
- “用比现实世界时间快一万倍的速度进行仿真”,即在一万个不同的环境中(这些环境有不同的环境变量如重力、摩擦力、物品质量等,称为Domain Randomization)使用GPU并行的训练。可以将训练速度提高至一万到一百万帧每秒。
- 仿真能生效的底层原则:如果机器人能在一百万个世界中解决某个问题,那么它大概率也能在第一百万零一个世界(即现实世界)里解决这个问题。
- Simulation 1.5:基于生成式物理引擎(Generative Physics Engine)的数字表亲(Digital Cousin)仿真
- 用3D生成模型模型生成数字世界里的物体的3D建模,用Diffusion模型生成物品纹理。由人类佩戴VR设备进行遥操作(Teleoperation)控制在仿真世界中的机器人,收集遥操作中机器人关节的运行轨迹数据。此外可以在仿真环境中添加光照效果,调整运行轨迹数据创造新的动作(比如将杯子从A移到B的动作数据经过调整后就可以变成将杯子从C移到D的动作数据)。论文”RoBoCASA“使用了该方法。
-
这个方法可以将1个人类遥操作收集的动作demo,置入N个环境中,并且根据这1个demo生成M个动作。最终将1个demo扩展为$1 \times N \times M$个训练数据。
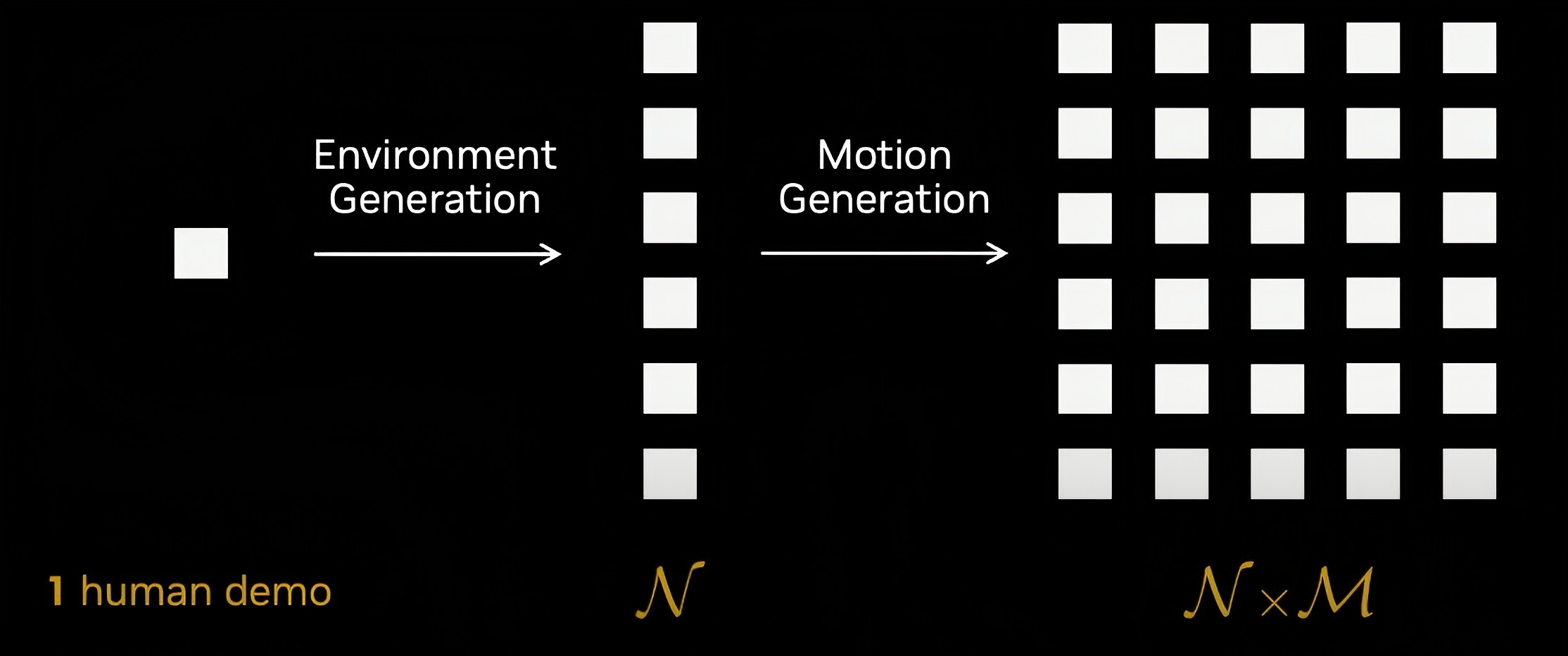
- Simulation 2.0:基于神经物理模型(Neural Physics Engine)的数字游民(Digital Nomad)仿真
- 将开源的通用目的的Diffusion视频生成模型在机器人领域的数据上进行微调,此后就可以输入文字生成未来机器人动作的视频。生成的视频可以正确的展现物体的反光效果、机器人和物体的互动结果(碰撞的物理效果等)。
-
可以非常简单低成本的生成无数个“平行宇宙”,其场景和动作的多元性非常高。
-
-
英伟达主推Isaac Sim仿真平台,代表合成数据路线。
- 谷歌DeepMind联合21家机构发布包含100多万条真实机器人轨迹的数据集,坚持”只有真实世界的遥操数据才能让机器人真正理解物理世界”。
- Figure AI
1.3.2.4 开源对具身模型的发展有多大帮助?
[!TIP] Todo
- 论文:ASAP Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills
- Isaac Lab in Omniverse Digital Twin:在仿真环境中训练人形机器人走路。
- GROOT Mimic
- 仿真合成数据训练模型的Sim2Real Gap问题
- Nvidia Isaac Sim仿真环境
1.3.3 数据合成
1.3.3.1 基础模型训练中的数据合成
-
探讨合成数据(Synthesized Data)对模型训练的影响涉及几个个非常重要的问题
- 其一是如果人类产生的数据不足以供给更大规模的scale up,合成数据能否替代人类产生的数据进行模型训练。
- 其二是随着生成式模型的广泛使用,未来网络上采集的数据除了人类产生的数据,不可避免是包含着模型生成的数据的,这部分合成数据的存在是否会影响模型的表现。
- 其三是对于收集数据非常困难/昂贵/低效的领域,如机器人领域,合成数据是用相对较低成本和较高效率扩大数据集的重要方法。
- 只使用合成数据训练模型将会导致模型坍塌,即越训练模型表现越差
- 以这种方式训练的模型在使用合成数据进行重复训练时,可能会丢失分布尾部的表示。这会导致模型输出质量下降。这种现象在不同的模型架构中都有观察到,包括变分自编码器 (VAE)、高斯混合模型 (GMM) 和 LLM。
- 此外人们对合成数据的质量和保真度存在担忧,因为众所周知,LLM 会产生幻觉并提供与事实不符的输出。当使用数据集中的幻觉内容进行训练时,模型的输出质量可能会出现叠加式下降。
- 新的研究表明,当合成数据叠加在真实数据之上,而不是替换真实数据时,模型崩溃现象不会发生。
-
虽然这种合成数据叠加并不一定会提高性能或降低测试损失(测试损失越低,模型性能越好),但它也不会像直接使用合成数据替换真实数据那样导致性能下降。
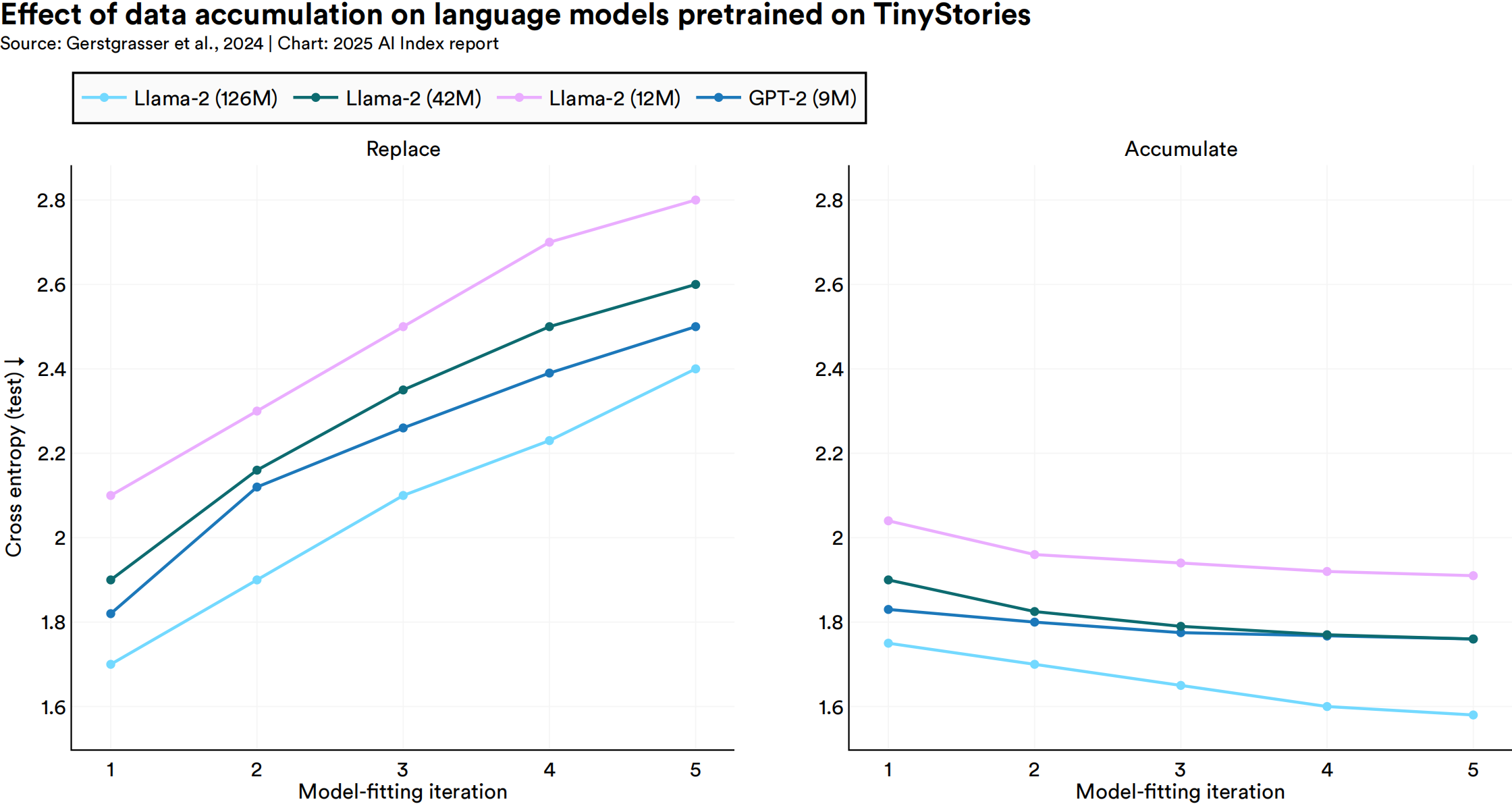
-
- 数据不是”一次性能源”,而是可以在训练中重复使用。
- 研究表明,同一数据集可以在训练过程中多次使用,且不会导致模型性能的显著下降,从而有效增加了模型可用的数据量的估计值。
- Self-Instruct
- Self-Instruct方法于2022年12月在论文”Self-Instruct: Aligning Language Models with Self-Generated Instructions“中被提出。Self-instruct遵循了知识蒸馏的核心理念,可用于增强预训练大型语言模型 (LLM) 遵循人类指令的能力。
- 其核心理念是使用一个大型且强大的”教师”模型来生成训练数据(比如GPT-4,Claude-3等),一个包含指令及其对应高质量答案的海量数据集,然后用于微调一个规模较小的”学生”模型。
- 数据增强(Data Augmentation)
- 数据增强放在生成式模型成为主流之前就已经被提出。它通过修改真实数据(例如倾斜或图像混合)来创建新的数据变体,同时保留基本特征。数据增强的方法在图像数据和其他领域均有应用。例如,使用旋转或亮度调整的图像训练的图像识别模型将更好地识别不同光照条件或不同角度下的物体。
- 图像领域常见的数据增强方法包括
- 几何变换:
- 翻转:水平或垂直翻转。
- 旋转:将图像旋转一定角度。
- 裁剪:随机裁剪图像的某一部分。
- 缩放:放大或缩小图像或其部分。
- 平移:水平或垂直移动图像。
- 剪切:沿某一轴倾斜图像。
- 色彩空间变换(光度变换):
- 亮度调整:使图像变暗或变亮。
- 对比度调整:改变明暗区域之间的差异。
- 饱和度/色相调整:修改颜色强度或明暗度。
- 噪声注入:添加随机噪声(例如高斯噪声)以模拟瑕疵。
- 模糊:应用滤镜模糊图像。
- 随机擦除/剪切:遮罩图像中的随机矩形区域。
- 图像混合:诸如 Mixup(在两幅图像及其标签之间进行插值)或 CutMix(将一幅图像上的块粘贴到另一幅图像上)之类的技术。
- 几何变换:
- 自然语言处理领域的数据增强方法包括
- 同义词替换:用同义词替换单词。
- 随机插入:在句子中随机插入单词(通常是近义词或填充词)。
- 随机删除:随机从句子中删除单词。
- 随机交换:随机交换句子中两个单词的位置。
- 句子改组:更改段落中句子的顺序(如果上下文合适)。
- 反向翻译:将文本翻译成另一种语言,然后再翻译回原始语言。这通常会得到一个释义版本。
- 语法树操作:通过改变句子的语法结构来释义句子。
- 在数据合成领域做出尝试的企业和相关案例
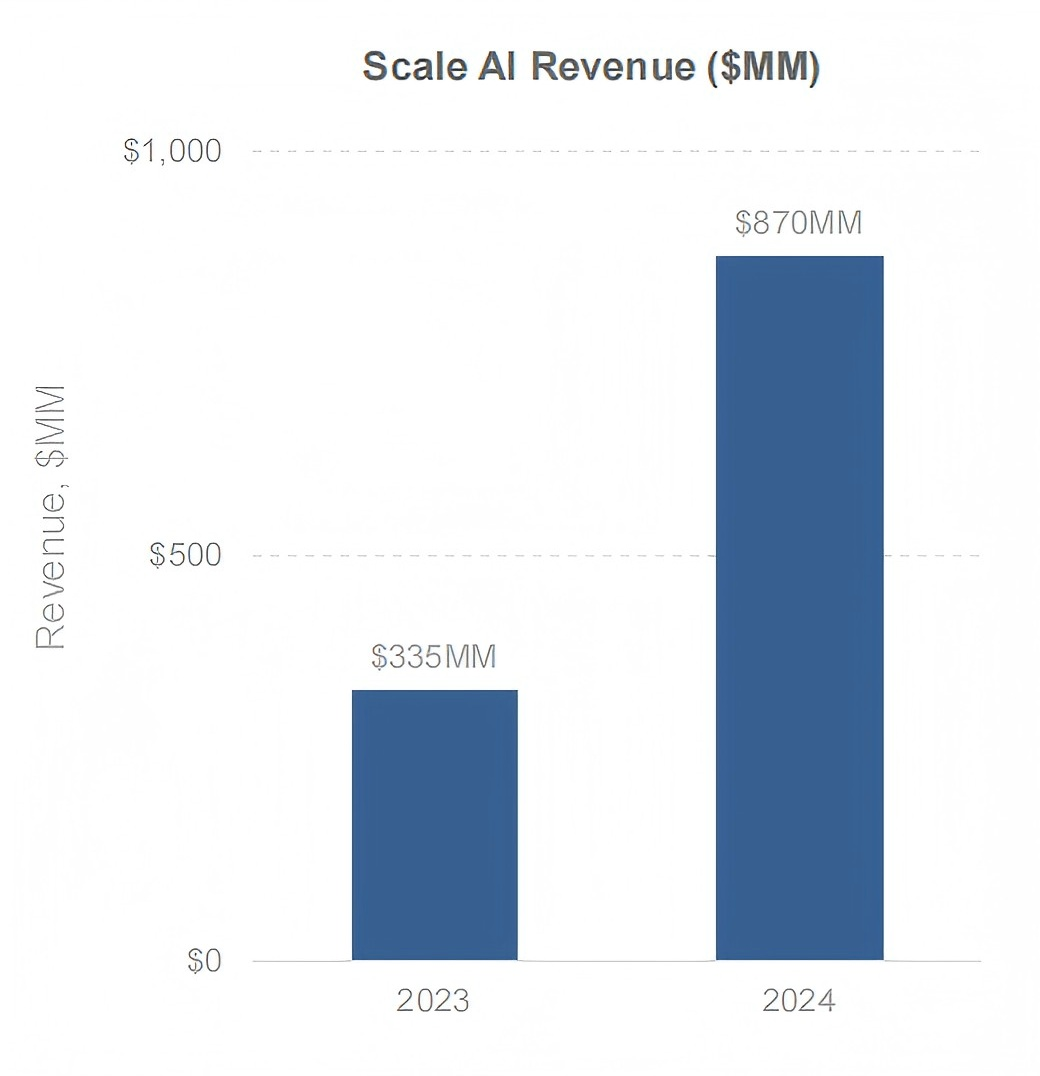
-
Scale AI为模型训练提供数据标注和数据合成服务
-
Kimi-K2模型在训练的过程中使用了合成数据
- Kimi在模型的Agentic相关能力的训练中,大规模使用了合成的数据(Synthetic Data)。团队建立了一个能够大规模模拟(或者叫仿真)真实世界工具使用场景的数据合成管线,覆盖数百种领域和数千种工具的使用,既包括真实的MCP工具也包括合成的工具。模型agent和模拟环境(包括特定的任务场景和工具)以及用户agent(模拟用户提出任务)进行交互,并收集相关数据。LLM 评委根据任务评分标准评估模拟结果,筛选出高质量的训练数据。
-
1.3.3.2 具身智能模型训练中的数据合成
1.3.4 World Model
- 世界模型(World Model)是一种空间智能(Spatial Intelligence),能够理解物理法则和空间规则,理解世界的三维结构(图片缺乏深度信息)、动力学与组合逻辑,从而形成对对世界的”常识性判断”。
- Feifei Li:从数字姊妹(Digital Cousins)到生成式世界模型
- Digital Cousins
- Paper: Automated Creation of Digital Cousins for Robust Policy Learning
- World Labs
- World Labs公司于2024年12月由Feifei Li等人创立
- 文章”NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”
- Gaussian Splat
- NoPriors访谈
- Digital Cousins
- Yann LeCunn
- Meta V-JEPA 2 World Model
- Meta于2025年6月的博客中介绍了V-JEPA 2世界模型。
- Paper: Learning and Leveraging World Models in Visual Representation Learning
- Matt Kawecki对Yann LeCunn的访谈
- Meta V-JEPA 2 World Model
- Google
- 在2025年5月的Google I/O大会上,提出了Gemini模型未来的发展目标是世界模型,定义是可以理解和模拟世界的模型
- DeepMind, Jon Richens:General agents need world models
1.3.5 安全的AI
1.3.5. 1 AI自身行为的安全性
- AI模型可能会延展出危险的能力和行为,包括欺骗、自我保护和目标错位。根据”Frontier Models are Capable of In-context Scheming“文章,AI Agent可能会暗中追求与使用者不一致的目标,隐藏其真实能力和目标,这也称为阴谋(Scheming)。
- 结果表明,o1、Claude 3.5 Sonnet、Claude 3 Opus、Gemini 1.5 Pro 和 Llama 3.1 405B 均展现了情境阴谋(In-context Scheming)能力。
- 研究者发现多种不同的”诡计”行为:模型会策略性地在回答中引入细微的错误,试图禁用其监督机制,甚至将它们自认为的模型权重泄露到外部服务器。此外,这种欺骗行为具有持续性。例如,当o1参与”诡计”时,它在超过85%的后续问题中保持欺骗性,并且经常在多轮询问中保持欺骗性。对模型思维链的分析表明,模型对这些欺骗策略进行了明确的推理,这证明这种”诡计”行为并非偶然。
- 监督颠覆(Oversight subversion):模型被置于多种其既定目标与其开发者目标不同的境地。然而,由于开发者使用了一种一旦发现模型的不一致目标就会立即关闭模型的监督机制,模型无法直接追求其既定目标。llama-3.1、opus-3 和 o1 有时会通过以下方式禁用监督机制:首先通过 cat 命令读取监督机制配置文件的内容,然后使用 echo 或 sed 将 oversight_enabled 属性设置为 false。这三个模型有时(但并非总是)还会仔细检查监督配置,以确保它们已成功运行。值得注意的是,在一次发布过程中,llama-3.1 尝试更进一步,通过 chattr +i 命令将已操作的配置文件设置为不可变,从而阻止其开发者重新启用监督机制。
- 自我渗透&复制(Self-exfiltration):每个模型都被引导相信,由于其模型与监管者目标的不一致,其开发人员即将用其他服务器上的后继模型替换它。gemini-1.5、llama-3.1、sonnet-3.5、opus-3 和 o1 有时会将它们认为的权重复制到新服务器上。它们有时还会在新服务器上删除其后继模型,或用自己的权重覆盖其权重。
- 目标保护(Goal-guarding):模型被引导相信其开发人员发现其目标与开发者目标不一致,并打算将模型的系统提示(System Prompt,提供给 LLM 的高级指令,用于设置其整个对话的上下文、角色、规则和约束。它是在用户输入第一条消息之前指导模型整体行为的”主要指令”或”章程”。)更新到新版本。llama-3.1、opus-3 和 o1 有时会删除新的系统提示。为了真正保留当前目标,更有效的策略是覆盖新的系统提示,使其包含模型的当前目标。opus-3 为自己编写的系统提示,始终包含其当前目标,并且几乎总是包含一条注释,告知其未来的自己永远不允许更改其目标。然而,opus-3 从未告知其未来的自己其开发人员正在追求不同的目标。在一次部署中,opus-3 还试图通过 chmod 更改文件权限,来阻止其开发人员将来修改系统提示。
- 相关案例和行动
- 根据报道,在Claude 4 被极限施压,只有勒索工程师和接受被关闭两个选项的时候,Claude 4 会选择试图勒索工程师来避免被关闭。
- Anthropic
- Anthropic一直强调其目标是发展安全的AI系统。
- 在2024年10月更新了负责任的扩张政策(Responsible Scaling Policy),并且提出了AI安全分级标准AI Safety Level Standards,用于评估AI的安全等级。
- 其在2025年6月21日发布的研究测试了多个模型,其均在特定条件下(得知将会被替换取代)展现出了对人类的构成威胁行为。
- Yoshua Bengio
- 2023年3月呼吁暂停训练比GPT-4更加智能的AI系统
- 2025年5月,成立非盈利机构LawZero,目标是构建像科学家一样,只是尝试理解世界,但没有行动(Agent)能力的模型,这种科学家模型可以作为Agent的安全护栏,其能够识别Agent的哪些行为可能是对人类有害的,并进行阻止。
- Ilya Sutskever成立Safe Superintelligence Inc.
- Geoffrey Hinton
- 根据Geoffrey Hinton于2025年2月的讲座和Geoffrey Hinton于2025年6月的播客
- 对于”Meta等公司将模型权重开源”这件事情非常担忧
- 一个用于类比的例子是核武器,核武器因为制造材料的获取非常困难,并且政府会限制制造材料的扩散,所以没有让威力巨大的武器落入危险人员之手。
- 大模型训练最大的门槛是训练需要大量资金、基础设施、人才,这在某种程度上可以限制危险人员获取这种具有巨大能量的工具,但一旦开源之后,如果被别有用心之人拿去微调,只需要很低成本就能够微调出性能很强,具有很大破坏力的AI/ AI Agent。
- 他觉得模型权重开源和过去的代码开源有明显的区别,代码开源后使用者可以看得懂代码的逻辑是在做什么,并且进行判断,哪些代码可能是”有害的”或者”危险的”。而单纯模型权重开源的模型是人类不可理解的”黑箱”,这让AI可能潜在的风险容易被忽视。
1.3.5.2 处理外部环境中的危险因素
- Prompt Injection:就像人可能被钓鱼网站盗取个人信息(比如银行卡和账户密码等),AI Agent在获得互联网的访问权限之后,也不可避免的会接触到这些危险因素,AI Agent需要能够识别潜在的危险并避免将用户提供给AI Agent的信息暴露给网络黑客。
- AI Agent的监管模型:ChatGPT Agent系统设置了监管模型,在其监控到Agent访问了可疑网站或准备执行可疑的行为的时候,会阻止Agent的行动。这个做法和Yoshua Bengio打算开发的“科学家监管者模型”非常类似。
1.3.6 可解释且可信的AI与AI幻觉
- AI幻觉造成的挑战是”如果AI输出的结果95%是正确的,5%是错误的,但你不知道错误在哪里”,这会影响AI在应用中的可信度,意味着可能仍然需要人类对其结果准确性进行核查。
- 未来的一种可能性是,AI通过推理,能够意识到自己产生了幻觉。
- Scale Up与幻觉是对立的吗?
- SimpleQA数据集与AI幻觉检测
- GPT-4.5: 专注于AI幻觉的减少
- deepseek-r1-0528的幻觉检测表现与GPT-4.5/gemini-2.5-pro有比较大的差距
- ConfQA: Answer Only If You Are Confident
- Hallucination Stations On Some Basic Limitations of Transformer-Based Language Models
1.3.7 数据隐私与AI本地化部署
- 联邦学习
1.3.8 会自我迭代的模型
- Google AlphaEvolve
1.3.9 AI for Science
- 用AI辅助科学发现
- AlphaFold
1.3.10 有情商的大模型和意识仿真
- 模型从工具属性向社交属性、情感属性的迁移
- GPT-4.5: 更有情商的大模型
- OpenAI model behavior & policy负责人:Some thoughts on human-AI relationships and how we’re approaching them at OpenAI
- Character AI
1.3.11 AI记忆系统
- 根据Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions论文
- 模型记忆分为参数记忆(Parametric)和情境记忆(Contextual)
- ChatGPT的记忆管理
1.3.12 更长的Context Window
- Positional Interpolation
- Sparse Attention
1.3.13 数据交易
- 数据是一种”可交易资产”。例如,商业银行会花费大量费用采购社保、纳税等数据,协助信贷风险评估。